Spatial DataFrame / SQL app
The page outlines the steps to manage spatial data using SedonaSQL.
Note
Sedona assumes geographic coordinates to be in longitude/latitude order. If your data is lat/lon order, please use ST_FlipCoordinates to swap X and Y.
SedonaSQL supports SQL/MM Part3 Spatial SQL Standard. It includes four kinds of SQL operators as follows. All these operators can be directly called through:
var myDataFrame = sedona.sql("YOUR_SQL")
myDataFrame.createOrReplaceTempView("spatialDf")
Dataset<Row> myDataFrame = sedona.sql("YOUR_SQL")
myDataFrame.createOrReplaceTempView("spatialDf")
myDataFrame = sedona.sql("YOUR_SQL")
myDataFrame.createOrReplaceTempView("spatialDf")
Detailed SedonaSQL APIs are available here: SedonaSQL API. You can find example county data (i.e., county_small.tsv) in Sedona GitHub repo.
Set up dependencies¶
- Read Sedona Maven Central coordinates and add Sedona dependencies in build.sbt or pom.xml.
- Add Apache Spark core, Apache SparkSQL in build.sbt or pom.xml.
- Please see SQL example project
- Please read Quick start to install Sedona Python.
- This tutorial is based on Sedona SQL Jupyter Notebook example.
Create Sedona config¶
Use the following code to create your Sedona config at the beginning. If you already have a SparkSession (usually named spark) created by AWS EMR/Databricks/Microsoft Fabric, please skip this step.
You can add additional Spark runtime config to the config builder. For example, SedonaContext.builder().config("spark.sql.autoBroadcastJoinThreshold", "10485760")
import org.apache.sedona.spark.SedonaContext
val config = SedonaContext.builder()
.master("local[*]") // Delete this if run in cluster mode
.appName("readTestScala") // Change this to a proper name
.getOrCreate()
SedonaContext.builder() to enable Sedona Kryo serializer:
.config("spark.kryo.registrator", classOf[SedonaVizKryoRegistrator].getName) // org.apache.sedona.viz.core.Serde.SedonaVizKryoRegistrator
import org.apache.sedona.spark.SedonaContext;
SparkSession config = SedonaContext.builder()
.master("local[*]") // Delete this if run in cluster mode
.appName("readTestJava") // Change this to a proper name
.getOrCreate()
SedonaContext.builder() to enable Sedona Kryo serializer:
.config("spark.kryo.registrator", SedonaVizKryoRegistrator.class.getName()) // org.apache.sedona.viz.core.Serde.SedonaVizKryoRegistrator
from sedona.spark import *
config = SedonaContext.builder() .\
config('spark.jars.packages',
'org.apache.sedona:sedona-spark-shaded-3.3_2.12:1.9.1,'
'org.datasyslab:geotools-wrapper:1.9.1-33.5'). \
getOrCreate()
3.3 in package name of sedona-spark-shaded with the corresponding major.minor version of Spark, such as sedona-spark-shaded-3.4_2.12:1.9.1.
Initiate SedonaContext¶
Add the following line after creating Sedona config. If you already have a SparkSession (usually named spark) created by AWS EMR/Databricks/Microsoft Fabric, please call sedona = SedonaContext.create(spark) instead.
import org.apache.sedona.spark.SedonaContext
val sedona = SedonaContext.create(config)
import org.apache.sedona.spark.SedonaContext;
SparkSession sedona = SedonaContext.create(config)
from sedona.spark import *
sedona = SedonaContext.create(config)
You can also register everything by passing --conf spark.sql.extensions=org.apache.sedona.sql.SedonaSqlExtensions to spark-submit or spark-shell.
Load data from text files¶
Assume we have a WKT file, namely usa-county.tsv, at Path /Download/usa-county.tsv as follows:
POLYGON (..., ...) Cuming County
POLYGON (..., ...) Wahkiakum County
POLYGON (..., ...) De Baca County
POLYGON (..., ...) Lancaster County
The file may have many other columns.
Load the raw DataFrame¶
Use the following code to load the data and create a raw DataFrame:
var rawDf = sedona.read.format("csv").option("delimiter", "\t").option("header", "false").load("/Download/usa-county.tsv")
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
Dataset<Row> rawDf = sedona.read.format("csv").option("delimiter", "\t").option("header", "false").load("/Download/usa-county.tsv")
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
rawDf = sedona.read.format("csv").option("delimiter", "\t").option("header", "false").load("/Download/usa-county.tsv")
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
The output will be like this:
| _c0|_c1|_c2| _c3| _c4| _c5| _c6|_c7|_c8| _c9|_c10| _c11|_c12|_c13| _c14| _c15| _c16| _c17|
+--------------------+---+---+--------+-----+-----------+--------------------+---+---+-----+----+-----+----+----+----------+--------+-----------+------------+
|POLYGON ((-97.019...| 31|039|00835841|31039| Cuming| Cuming County| 06| H1|G4020|null| null|null| A|1477895811|10447360|+41.9158651|-096.7885168|
|POLYGON ((-123.43...| 53|069|01513275|53069| Wahkiakum| Wahkiakum County| 06| H1|G4020|null| null|null| A| 682138871|61658258|+46.2946377|-123.4244583|
|POLYGON ((-104.56...| 35|011|00933054|35011| De Baca| De Baca County| 06| H1|G4020|null| null|null| A|6015539696|29159492|+34.3592729|-104.3686961|
|POLYGON ((-96.910...| 31|109|00835876|31109| Lancaster| Lancaster County| 06| H1|G4020| 339|30700|null| A|2169240202|22877180|+40.7835474|-096.6886584|
Create a Geometry type column¶
All geometrical operations in SedonaSQL are on Geometry type objects. Therefore, before any kind of queries, you need to create a Geometry type column on a DataFrame.
SELECT ST_GeomFromWKT(_c0) AS countyshape, _c1, _c2
You can select many other attributes to compose this spatialdDf. The output will be something like this:
| countyshape|_c1|_c2| _c3| _c4| _c5| _c6|_c7|_c8| _c9|_c10| _c11|_c12|_c13| _c14| _c15| _c16| _c17|
+--------------------+---+---+--------+-----+-----------+--------------------+---+---+-----+----+-----+----+----+----------+--------+-----------+------------+
|POLYGON ((-97.019...| 31|039|00835841|31039| Cuming| Cuming County| 06| H1|G4020|null| null|null| A|1477895811|10447360|+41.9158651|-096.7885168|
|POLYGON ((-123.43...| 53|069|01513275|53069| Wahkiakum| Wahkiakum County| 06| H1|G4020|null| null|null| A| 682138871|61658258|+46.2946377|-123.4244583|
|POLYGON ((-104.56...| 35|011|00933054|35011| De Baca| De Baca County| 06| H1|G4020|null| null|null| A|6015539696|29159492|+34.3592729|-104.3686961|
|POLYGON ((-96.910...| 31|109|00835876|31109| Lancaster| Lancaster County| 06| H1|G4020| 339|30700|null| A|2169240202|22877180|+40.7835474|-096.6886584|
Although it looks same with the input, but actually the type of column countyshape has been changed to Geometry type.
To verify this, use the following code to print the schema of the DataFrame:
spatialDf.printSchema()
The output will be like this:
root
|-- countyshape: geometry (nullable = false)
|-- _c1: string (nullable = true)
|-- _c2: string (nullable = true)
|-- _c3: string (nullable = true)
|-- _c4: string (nullable = true)
|-- _c5: string (nullable = true)
|-- _c6: string (nullable = true)
|-- _c7: string (nullable = true)
Note
SedonaSQL provides lots of functions to create a Geometry column, please read SedonaSQL constructor API.
Load GeoJSON Data¶
Since v1.6.1, Sedona supports reading GeoJSON files using the geojson data source. It is designed to handle JSON files that use GeoJSON format for their geometries.
Set the multiLine option to True to read multiline GeoJSON files.
df = (
sedona.read.format("geojson")
.option("multiLine", "true")
.load("PATH/TO/MYFILE.json")
.selectExpr("explode(features) as features") # Explode the envelope
.select("features.*") # Unpack the features struct
.withColumn("prop0", f.expr("properties['prop0']"))
.drop("properties")
.drop("type")
)
df.show()
df.printSchema()
val df = sedona.read.format("geojson").option("multiLine", "true").load("PATH/TO/MYFILE.json")
val parsedDf = df.selectExpr("explode(features) as features").select("features.*")
.withColumn("prop0", expr("properties['prop0']")).drop("properties").drop("type")
parsedDf.show()
parsedDf.printSchema()
Dataset<Row> df = sedona.read.format("geojson").option("multiLine", "true").load("PATH/TO/MYFILE.json")
.selectExpr("explode(features) as features") // Explode the envelope to get one feature per row.
.select("features.*") // Unpack the features struct.
.withColumn("prop0", expr("properties['prop0']")).drop("properties").drop("type")
df.show();
df.printSchema();
See this page for more information on loading GeoJSON files.
Load Shapefile¶
Since v1.7.0, Sedona supports loading Shapefile as a DataFrame.
val df = sedona.read.format("shapefile").load("/path/to/shapefile")
Dataset<Row> df = sedona.read().format("shapefile").load("/path/to/shapefile")
df = sedona.read.format("shapefile").load("/path/to/shapefile")
The input path can be a directory containing one or multiple shapefiles, or path to a .shp file.
See this page for more information on loading Shapefiles.
Load GeoParquet¶
Since v1.3.0, Sedona natively supports loading GeoParquet file. Sedona will infer geometry fields using the "geo" metadata in GeoParquet files.
val df = sedona.read.format("geoparquet").load(geoparquetdatalocation1)
df.printSchema()
Dataset<Row> df = sedona.read.format("geoparquet").load(geoparquetdatalocation1)
df.printSchema()
df = sedona.read.format("geoparquet").load(geoparquetdatalocation1)
df.printSchema()
The output will be as follows:
root
|-- pop_est: long (nullable = true)
|-- continent: string (nullable = true)
|-- name: string (nullable = true)
|-- iso_a3: string (nullable = true)
|-- gdp_md_est: double (nullable = true)
|-- geometry: geometry (nullable = true)
Sedona supports spatial predicate push-down for GeoParquet files, please refer to the SedonaSQL query optimizer documentation for details.
GeoParquet file reader can also be used to read legacy Parquet files written by Apache Sedona 1.3.1-incubating or earlier. Please refer to Reading Legacy Parquet Files for details.
See this page for more information on loading GeoParquet.
Load data from STAC catalog¶
Sedona STAC data source allows you to read data from a SpatioTemporal Asset Catalog (STAC) API. The data source supports reading STAC items and collections.
You can load a STAC collection from a s3 collection file object:
df = sedona.read.format("stac").load(
"s3a://example.com/stac_bucket/stac_collection.json"
)
You can also load a STAC collection from an HTTP/HTTPS endpoint:
df = sedona.read.format("stac").load(
"https://earth-search.aws.element84.com/v1/collections/sentinel-2-pre-c1-l2a"
)
The STAC data source supports predicate pushdown for spatial and temporal filters. The data source can push down spatial and temporal filters to the underlying data source to reduce the amount of data that needs to be read.
See this page for more information on loading data from STAC.
Load data from JDBC data sources¶
The 'query' option in Spark SQL's JDBC data source can be used to convert geometry columns to a format that Sedona can interpret. This should work for most spatial JDBC data sources. For Postgis there is no need to add a query to convert geometry types since it's already using EWKB as it's wire format.
// For any JDBC data source, including Postgis.
val df = sedona.read.format("jdbc")
// Other options.
.option("query", "SELECT id, ST_AsBinary(geom) as geom FROM my_table")
.load()
.withColumn("geom", expr("ST_GeomFromWKB(geom)"))
// This is a simplified version that works for Postgis.
val df = sedona.read.format("jdbc")
// Other options.
.option("dbtable", "my_table")
.load()
.withColumn("geom", expr("ST_GeomFromWKB(geom)"))
// For any JDBC data source, including Postgis.
Dataset<Row> df = sedona.read().format("jdbc")
// Other options.
.option("query", "SELECT id, ST_AsBinary(geom) as geom FROM my_table")
.load()
.withColumn("geom", expr("ST_GeomFromWKB(geom)"))
// This is a simplified version that works for Postgis.
Dataset<Row> df = sedona.read().format("jdbc")
// Other options.
.option("dbtable", "my_table")
.load()
.withColumn("geom", expr("ST_GeomFromWKB(geom)"))
# For any JDBC data source, including Postgis.
df = (sedona.read.format("jdbc")
# Other options.
.option("query", "SELECT id, ST_AsBinary(geom) as geom FROM my_table")
.load()
.withColumn("geom", f.expr("ST_GeomFromWKB(geom)")))
# This is a simplified version that works for Postgis.
df = (sedona.read.format("jdbc")
# Other options.
.option("dbtable", "my_table")
.load()
.withColumn("geom", f.expr("ST_GeomFromWKB(geom)")))
Load GeoPackage¶
Since v1.7.0, Sedona supports loading Geopackage file format as a DataFrame.
val df = sedona.read.format("geopackage").option("tableName", "tab").load("/path/to/geopackage")
Dataset<Row> df = sedona.read().format("geopackage").option("tableName", "tab").load("/path/to/geopackage")
df = sedona.read.format("geopackage").option("tableName", "tab").load("/path/to/geopackage")
See this page for more information on loading GeoPackage.
Load OSM PBF¶
Since v1.7.1, Sedona supports loading OSM PBF file format as a DataFrame.
val df = sedona.read.format("osmpbf").load("/path/to/osmpbf")
Dataset<Row> df = sedona.read().format("osmpbf").load("/path/to/osmpbf")
df = sedona.read.format("osmpbf").load("/path/to/osmpbf")
OSM PBF files can contain nodes, ways, and relations. Currently Sedona support Nodes, DenseNodes, Ways and Relations. When you load the data you get a DataFrame with the following schema.
root
|-- id: long (nullable = true)
|-- kind: string (nullable = true)
|-- location: struct (nullable = true)
| |-- longitude: double (nullable = true)
| |-- latitude: double (nullable = true)
|-- tags: map (nullable = true)
| |-- key: string
| |-- value: string (valueContainsNull = true)
|-- refs: array (nullable = true)
| |-- element: long (containsNull = true)
|-- ref_roles: array (nullable = true)
| |-- element: string (containsNull = true)
|-- ref_types: array (nullable = true)
| |-- element: string (containsNull = true)
Where:
idis the unique identifier of the object.kindis the type of the object, it can benode,wayorrelation.locationis the location of the object, it contains thelongitudeandlatitudeof the object.tagsis a map of key-value pairs that represent the tags of the object.refsis an array of the references of the object.ref_rolesis an array of the roles of the references.ref_typesis an array of the types of the references.
The dataframe for ways might look like this for nodes:
+---------+----+--------------------+--------------------+----+---------+---------+
| id|kind| location| tags|refs|ref_roles|ref_types|
+---------+----+--------------------+--------------------+----+---------+---------+
|248675410|node|{21.0884952545166...|{tactile_paving -...|NULL| NULL| NULL|
|260821820|node|{21.0191555023193...|{created_by -> JOSM}|NULL| NULL| NULL|
|349189665|node|{22.1437530517578...|{source -> http:/...|NULL| NULL| NULL|
|353366899|node|{22.9787712097167...|{source -> http:/...|NULL| NULL| NULL|
|359460224|node|{22.4816703796386...|{source -> http:/...|NULL| NULL| NULL|
+---------+----+--------------------+--------------------+----+---------+---------+
only showing top 5 rows
and for way
+-------+----+--------+--------------------+--------------------+---------+---------+
| id|kind|location| tags| refs|ref_roles|ref_types|
+-------+----+--------+--------------------+--------------------+---------+---------+
|4307329| way| NULL|{junction -> roun...|[2448759046, 7093...| NULL| NULL|
|4307330| way| NULL|{surface -> aspha...|[26063923, 260639...| NULL| NULL|
|4308966| way| NULL|{sidewalk -> sepa...|[3387797238, 9252...| NULL| NULL|
|4308968| way| NULL|{surface -> pavin...|[26083890, 744724...| NULL| NULL|
|4308969| way| NULL|{cycleway:both ->...|[9526831176, 1218...| NULL| NULL|
+-------+----+--------+--------------------+--------------------+---------+---------+
and for relation
+-----+--------+--------+--------------------+--------------------+--------------------+--------------------+
| id| kind|location| tags| refs| ref_roles| ref_types|
+-----+--------+--------+--------------------+--------------------+--------------------+--------------------+
|28124|relation| NULL|{official_name ->...|[26382394, 26259985]| [inner, outer]| [WAY, WAY]|
|28488|relation| NULL| {type -> junction}|[26409253, 303249...|[roundabout, roun...|[WAY, WAY, WAY, WAY]|
|32939|relation| NULL|{ref -> E 67, rou...|[140673970, 14067...| [, , , , , ]|[WAY, WAY, RELATI...|
|34387|relation| NULL|{note -> rząd III...|[209161000, 52154...|[main_stream, mai...|[WAY, WAY, WAY, W...|
|34392|relation| NULL|{distance -> 1047...|[150033976, 25076...|[main_stream, mai...|[WAY, WAY, WAY, W...|
+-----+--------+--------+--------------------+--------------------+--------------------+--------------------+
Transform the Coordinate Reference System¶
Sedona doesn't control the coordinate unit (degree-based or meter-based) of all geometries in a Geometry column. The unit of all related distances in SedonaSQL is same as the unit of all geometries in a Geometry column.
By default, this function uses lon/lat order since v1.5.0. Before, it used lat/lon order. You can use ST_FlipCoordinates to swap X and Y.
For more details, please read the ST_Transform section in Sedona API References.
To convert Coordinate Reference System of the Geometry column created before, use the following code:
SELECT ST_Transform(countyshape, "epsg:4326", "epsg:3857") AS newcountyshape, _c1, _c2, _c3, _c4, _c5, _c6, _c7
FROM spatialdf
The first EPSG code EPSG:4326 in ST_Transform is the source CRS of the geometries. It is WGS84, the most common degree-based CRS.
The second EPSG code EPSG:3857 in ST_Transform is the target CRS of the geometries. It is the most common meter-based CRS.
This ST_Transform transform the CRS of these geometries from EPSG:4326 to EPSG:3857. The details CRS information can be found on EPSG.io
The coordinates of polygons have been changed. The output will be like this:
+--------------------+---+---+--------+-----+-----------+--------------------+---+
| newcountyshape|_c1|_c2| _c3| _c4| _c5| _c6|_c7|
+--------------------+---+---+--------+-----+-----------+--------------------+---+
|POLYGON ((-108001...| 31|039|00835841|31039| Cuming| Cuming County| 06|
|POLYGON ((-137408...| 53|069|01513275|53069| Wahkiakum| Wahkiakum County| 06|
|POLYGON ((-116403...| 35|011|00933054|35011| De Baca| De Baca County| 06|
|POLYGON ((-107880...| 31|109|00835876|31109| Lancaster| Lancaster County| 06|
Cluster with DBSCAN¶
Sedona provides an implementation of the DBSCAN algorithm to cluster spatial data.
The algorithm is available as a Scala and Python function called on a spatial dataframe. The returned dataframe has an additional column added containing the unique identifier of the cluster that record is a member of and a boolean column indicating if the record is a core point.
The first parameter is the dataframe, the next two are the epsilon and min_points parameters of the DBSCAN algorithm.
import org.apache.sedona.stats.clustering.DBSCAN.dbscan
dbscan(df, 0.1, 5).show()
import org.apache.sedona.stats.clustering.DBSCAN;
DBSCAN.dbscan(df, 0.1, 5).show();
from sedona.spark.stats import dbscan
dbscan(df, 0.1, 5).show()
The output will look like this:
+----------------+---+------+-------+
| geometry| id|isCore|cluster|
+----------------+---+------+-------+
| POINT (2.5 4)| 3| false| 1|
| POINT (3 4)| 2| false| 1|
| POINT (3 5)| 5| false| 1|
| POINT (1 3)| 9| true| 0|
| POINT (2.5 4.5)| 7| true| 1|
| POINT (1 2)| 1| true| 0|
| POINT (1.5 2.5)| 4| true| 0|
| POINT (1.2 2.5)| 8| true| 0|
| POINT (1 2.5)| 11| true| 0|
| POINT (1 5)| 10| false| -1|
| POINT (5 6)| 12| false| -1|
|POINT (12.8 4.5)| 6| false| -1|
| POINT (4 3)| 13| false| -1|
+----------------+---+------+-------+
See this page for more information on the DBSCAN algorithm.
Calculate the Local Outlier Factor (LOF)¶
Sedona provides an implementation of the Local Outlier Factor algorithm to identify anomalous data.
The algorithm is available as a Scala and Python function called on a spatial dataframe. The returned dataframe has an additional column added containing the local outlier factor.
The first parameter is the dataframe, the next is the number of nearest neighbors to consider use in calculating the score.
import org.apache.sedona.stats.outlierDetection.LocalOutlierFactor.localOutlierFactor
localOutlierFactor(df, 20).show()
import org.apache.sedona.stats.outlierDetection.LocalOutlierFactor;
LocalOutlierFactor.localOutlierFactor(df, 20).show();
from sedona.spark.stats import local_outlier_factor
local_outlier_factor(df, 20).show()
The output will look like this:
+--------------------+------------------+
| geometry| lof|
+--------------------+------------------+
|POINT (-2.0231305...| 0.952098153363662|
|POINT (-2.0346944...|0.9975325496668104|
|POINT (-2.2040074...|1.0825843906411081|
|POINT (1.61573501...|1.7367129352162634|
|POINT (-2.1176324...|1.5714144683150393|
|POINT (-2.2349759...|0.9167275845938276|
|POINT (1.65470192...| 1.046231536764447|
|POINT (0.62624112...|1.1988700676990034|
|POINT (2.01746261...|1.1060219481067417|
|POINT (-2.0483857...|1.0775553430145446|
|POINT (2.43969463...|1.1129132178576646|
|POINT (-2.2425480...| 1.104108012697006|
|POINT (-2.7859235...| 2.86371824574529|
|POINT (-1.9738858...|1.0398822680356794|
|POINT (2.00153403...| 0.927409656346015|
|POINT (2.06422812...|0.9222203762264445|
|POINT (-1.7533819...|1.0273650471626696|
|POINT (-2.2030766...| 0.964744555830738|
|POINT (-1.8509857...|1.0375927869698574|
|POINT (2.10849080...|1.0753419197322656|
+--------------------+------------------+
Perform Getis-Ord Gi(*) Hot Spot Analysis¶
Sedona provides an implementation of the Gi and Gi* algorithms to identify local hotspots in spatial data
The algorithm is available as a Scala and Python function called on a spatial dataframe. The returned dataframe has additional columns added containing G statistic, E[G], V[G], the Z score, and the p-value.
Using Gi involves first generating the neighbors list for each record, then calling the g_local function.
import org.apache.sedona.stats.Weighting.addBinaryDistanceBandColumn
import org.apache.sedona.stats.hotspotDetection.GetisOrd.gLocal
val distanceRadius = 1.0
val weightedDf = addBinaryDistanceBandColumn(df, distanceRadius)
gLocal(weightedDf, "val").show()
import org.apache.sedona.stats.Weighting;
import org.apache.sedona.stats.hotspotDetection.GetisOrd;
import org.apache.spark.sql.DataFrame;
double distanceRadius = 1.0;
DataFrame weightedDf = Weighting.addBinaryDistanceBandColumn(df, distanceRadius);
GetisOrd.gLocal(weightedDf, "val").show();
from sedona.spark.stats import add_binary_distance_band_column
from sedona.spark.stats import g_local
distance_radius = 1.0
weighted_df = addBinaryDistanceBandColumn(df, distance_radius)
g_local(weightedDf, "val").show()
The output will look like this:
+-----------+---+--------------------+-------------------+-------------------+--------------------+--------------------+--------------------+
| geometry|val| weights| G| EG| VG| Z| P|
+-----------+---+--------------------+-------------------+-------------------+--------------------+--------------------+--------------------+
|POINT (2 2)|0.9|[{{POINT (2 3), 1...| 0.4488188976377953|0.45454545454545453| 0.00356321373799772|-0.09593402008347063| 0.4617864875295957|
|POINT (2 3)|1.2|[{{POINT (2 2), 0...|0.35433070866141736|0.36363636363636365|0.003325666155464539|-0.16136436037034918| 0.4359032175415549|
|POINT (3 3)|1.2|[{{POINT (2 3), 1...|0.28346456692913385| 0.2727272727272727|0.002850570990398176| 0.20110780337013057| 0.42030714022155924|
|POINT (3 2)|1.2|[{{POINT (2 2), 0...| 0.4488188976377953|0.45454545454545453| 0.00356321373799772|-0.09593402008347063| 0.4617864875295957|
|POINT (3 1)|1.2|[{{POINT (3 2), 3...| 0.3622047244094489| 0.2727272727272727|0.002850570990398176| 1.6758983614177538| 0.04687905137429871|
|POINT (2 1)|2.2|[{{POINT (2 2), 0...| 0.4330708661417323|0.36363636363636365|0.003325666155464539| 1.2040263812249166| 0.11428969105925013|
|POINT (1 1)|1.2|[{{POINT (2 1), 5...| 0.2834645669291339| 0.2727272727272727|0.002850570990398176| 0.2011078033701316| 0.4203071402215588|
|POINT (1 2)|0.2|[{{POINT (2 2), 0...|0.35433070866141736|0.45454545454545453| 0.00356321373799772| -1.67884535146075|0.046591093685710794|
|POINT (1 3)|1.2|[{{POINT (2 3), 1...| 0.2047244094488189| 0.2727272727272727|0.002850570990398176| -1.2736827546774914| 0.10138793530151635|
|POINT (0 2)|1.0|[{{POINT (1 2), 7...|0.09448818897637795|0.18181818181818182|0.002137928242798632| -1.8887168824332323|0.029464887612748458|
|POINT (4 2)|1.2|[{{POINT (3 2), 3...| 0.1889763779527559|0.18181818181818182|0.002137928242798632| 0.15481285921583854| 0.43848442662481324|
+-----------+---+--------------------+-------------------+-------------------+--------------------+--------------------+--------------------+
Run spatial queries¶
After creating a Geometry type column, you are able to run spatial queries.
Range query¶
Use ST_Contains, ST_Intersects, ST_Within to run a range query over a single column.
The following example finds all counties that are within the given polygon:
SELECT *
FROM spatialdf
WHERE ST_Contains (ST_PolygonFromEnvelope(1.0,100.0,1000.0,1100.0), newcountyshape)
Note
Read SedonaSQL constructor API to learn how to create a Geometry type query window
KNN query¶
Use ST_Distance to calculate the distance and rank the distance.
The following code returns the 5 nearest neighbor of the given polygon.
SELECT countyname, ST_Distance(ST_PolygonFromEnvelope(1.0,100.0,1000.0,1100.0), newcountyshape) AS distance
FROM spatialdf
ORDER BY distance DESC
LIMIT 5
Join query¶
The details of a join query is available here Join query.
KNN join query¶
The details of a KNN join query is available here KNN join query.
Other queries¶
There are lots of other functions can be combined with these queries. Please read SedonaSQL functions and SedonaSQL aggregate functions.
Visualize query results¶
Sedona provides SedonaPyDeck and SedonaKepler wrappers, both of which expose APIs to create interactive map visualizations from SedonaDataFrames in a Jupyter environment.
Note
Both SedonaPyDeck and SedonaKepler expect the default geometry order to be lon-lat. If your dataframe has geometries in the lat-lon order, please check out ST_FlipCoordinates
Note
Both SedonaPyDeck and SedonaKepler are designed to work with SedonaDataFrames containing only 1 geometry column. Passing dataframes with multiple geometry columns will cause errors.
SedonaPyDeck¶
Spatial query results can be visualized in a Jupyter lab/notebook environment using SedonaPyDeck.
SedonaPyDeck exposes APIs to create interactive map visualizations using pydeck based on deck.gl
Note
To use SedonaPyDeck, install sedona with the pydeck-map extra:
pip install apache-sedona[pydeck-map]
The following tutorial showcases the various maps that can be created using SedonaPyDeck, the datasets used to create these maps are publicly available.
Each API exposed by SedonaPyDeck offers customization via optional arguments, details on all possible arguments can be found in the API docs of SedonaPyDeck.
Creating a Choropleth map using SedonaPyDeck¶
SedonaPyDeck exposes a create_choropleth_map API which can be used to visualize a choropleth map out of the passed SedonaDataFrame containing polygons with an observation:
Example:
SedonaPyDeck.create_choropleth_map(df=groupedresult, plot_col="AirportCount")
Note
plot_col is a required argument informing SedonaPyDeck of the column name used to render the choropleth effect.
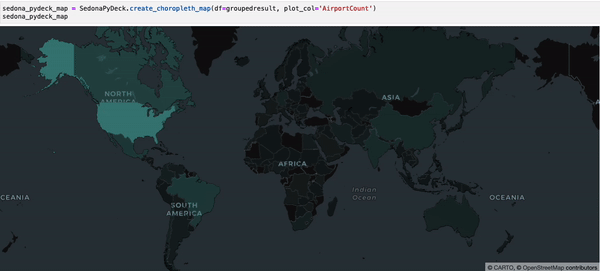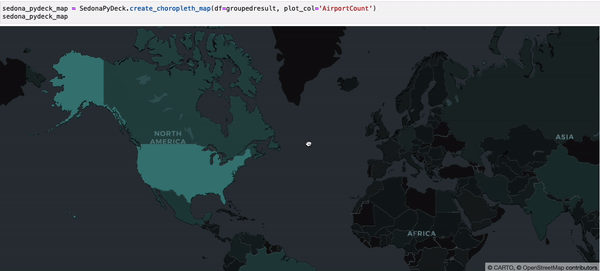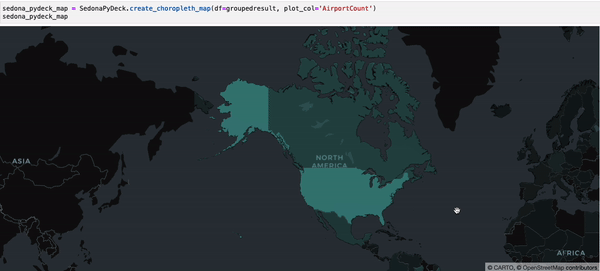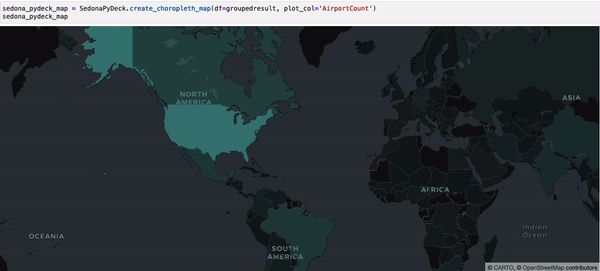
The dataset used is available here and can also be found in the example notebook available here
Creating a Geometry map using SedonaPyDeck¶
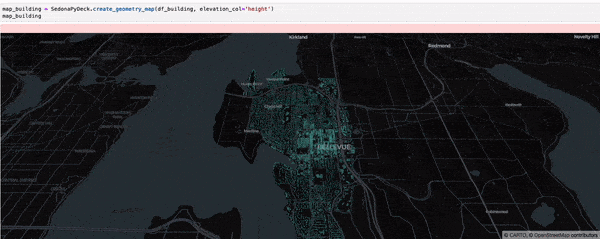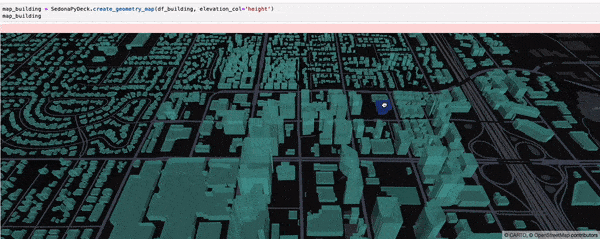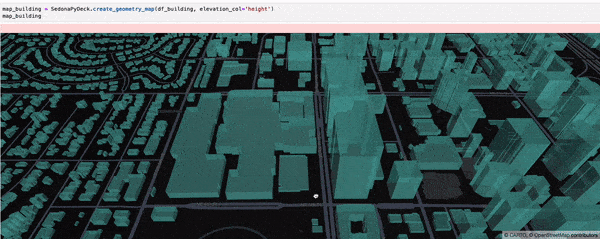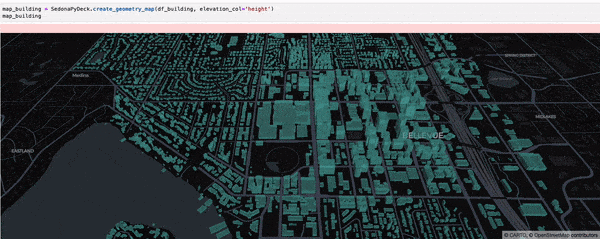
SedonaPyDeck exposes a create_geometry_map API which can be used to visualize a passed SedonaDataFrame containing any type of geometries:
Example:
SedonaPyDeck.create_geometry_map(df_building, elevation_col="height")
Tip
elevation_col is an optional argument which can be used to render a 3D map. Pass the column with 'elevation' values for the geometries here.
Creating a Scatterplot map using SedonaPyDeck¶
SedonaPyDeck exposes a create_scatterplot_map API which can be used to visualize a scatterplot out of the passed SedonaDataFrame containing points:
Example:
SedonaPyDeck.create_scatterplot_map(df=crimes_df)
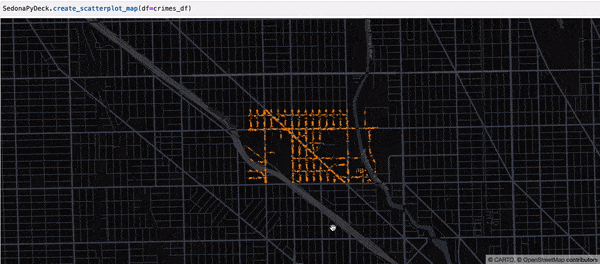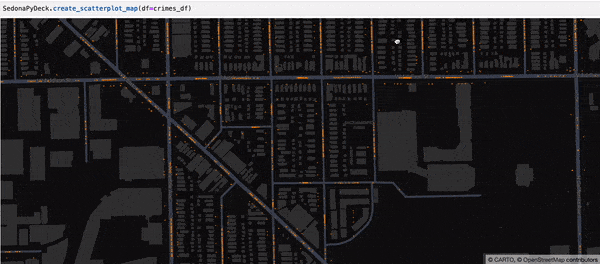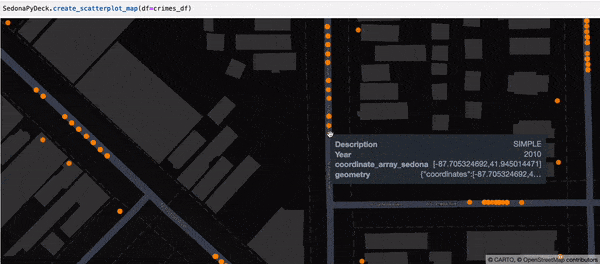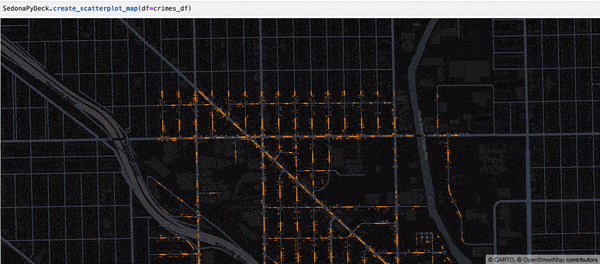
The dataset used here is the Chicago crimes dataset, available here
Creating a heatmap using SedonaPyDeck¶
SedonaPyDeck exposes a create_heatmap API which can be used to visualize a heatmap out of the passed SedonaDataFrame containing points:
Example:
SedonaPyDeck.create_heatmap(df=crimes_df)
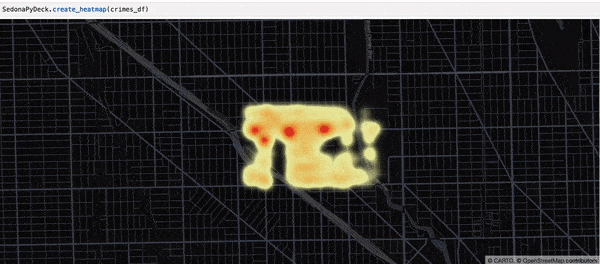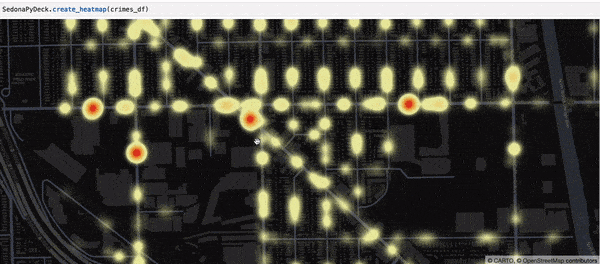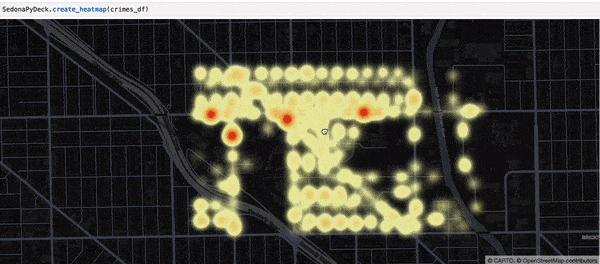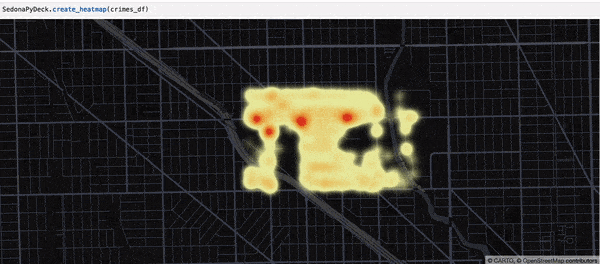
The dataset used here is the Chicago crimes dataset, available here
SedonaKepler¶
Spatial query results can be visualized in a Jupyter lab/notebook environment using SedonaKepler.
SedonaKepler exposes APIs to create interactive and customizable map visualizations using KeplerGl.
Note
To use SedonaKepler, install sedona with the kepler-map extra:
pip install apache-sedona[kepler-map]
This tutorial showcases how simple it is to instantly visualize geospatial data using SedonaKepler.
Example (referenced from an example notebook via the binder):
SedonaKepler.create_map(df=groupedresult, name="AirportCount")
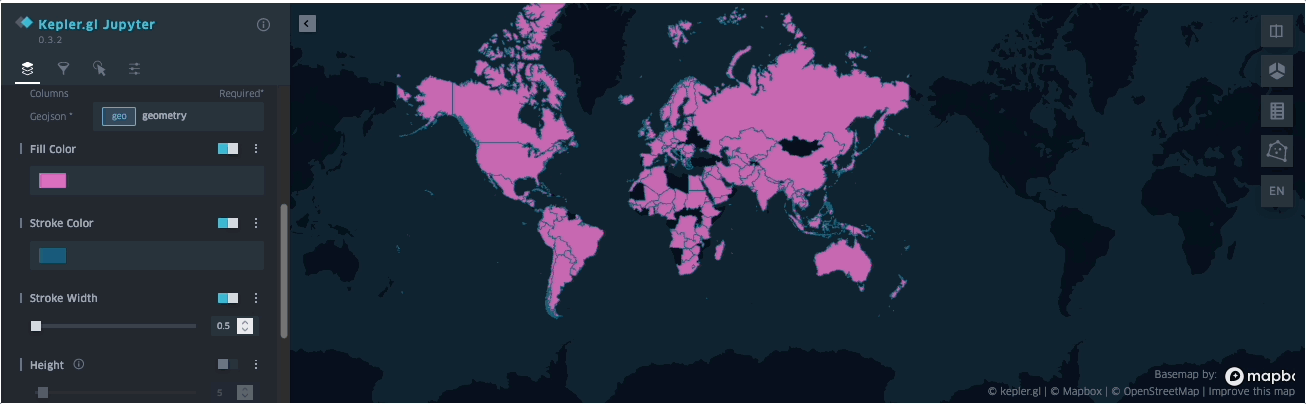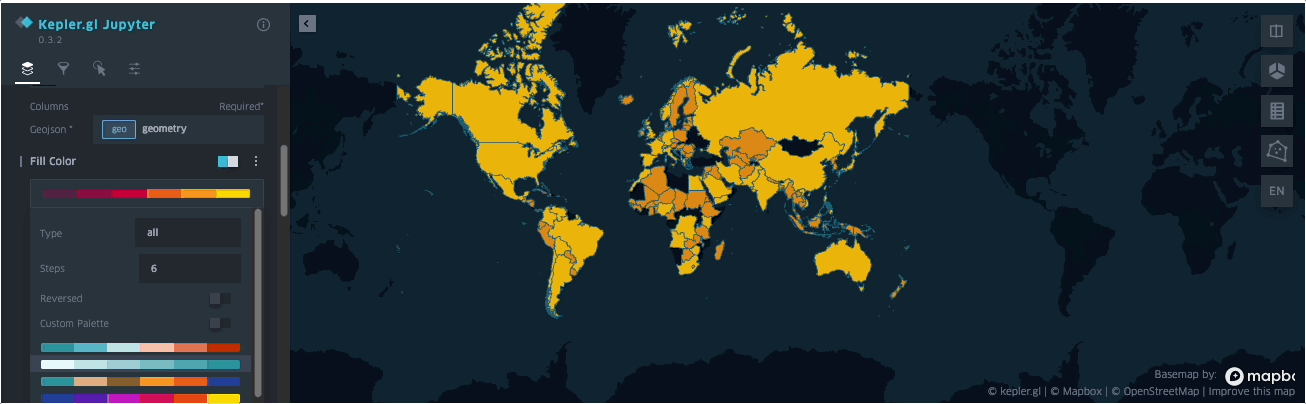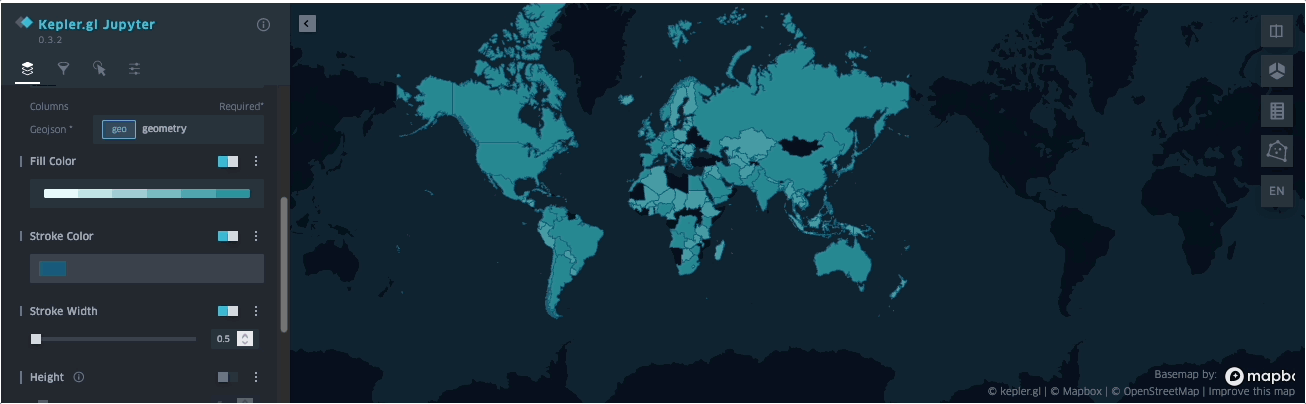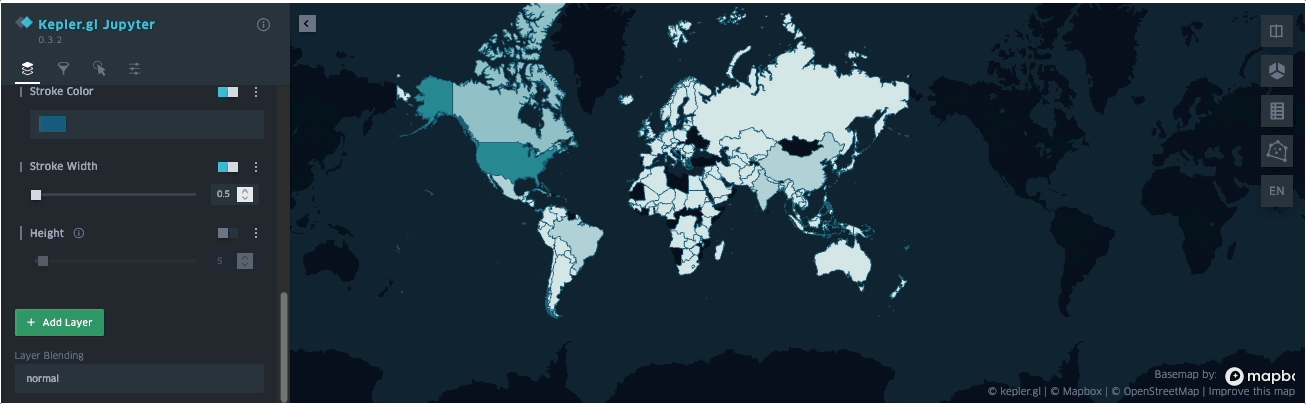
The dataset used is available here and can also be found in the example notebook available here
Details on all the APIs available by SedonaKepler are listed in the SedonaKepler API docs
Create a User-Defined Function (UDF)¶
User-Defined Functions (UDFs) are user-created procedures that can perform operations on a single row of information. To cover almost all use cases, we will showcase 4 types of UDFs for a better understanding of how to use geometry with UDFs. Sedona's serializer deserializes the SQL geometry type to JTS Geometry (Scala/Java) or Shapely Geometry (Python). You can implement any custom logic using the rich ecosystem around these two libraries.
Geometry to primitive¶
This UDF example takes a geometry type input and returns a primitive type output:
import org.locationtech.jts.geom.Geometry
import org.apache.spark.sql.types._
def lengthPoly(geom: Geometry): Double = {
geom.getLength
}
sedona.udf.register("udf_lengthPoly", lengthPoly _)
df.selectExpr("udf_lengthPoly(geom)").show()
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.types.DataTypes;
// using lambda function to register the UDF
sparkSession.udf().register(
"udf_lengthPoly",
(UDF1<Geometry, Double>) Geometry::getLength,
DataTypes.DoubleType);
df.selectExpr("udf_lengthPoly(geom)").show()
from sedona.spark.sql.types import GeometryType
from pyspark.sql.types import DoubleType
def lengthPoly(geom: GeometryType()):
return geom.length
sedona.udf.register("udf_lengthPoly", lengthPoly, DoubleType())
df.selectExpr("udf_lengthPoly(geom)").show()
Output:
+--------------------+
|udf_lengthPoly(geom)|
+--------------------+
| 3.414213562373095|
+--------------------+
Geometry to Geometry¶
This UDF example takes a geometry type input and returns a geometry type output:
import org.locationtech.jts.geom.Geometry
import org.apache.spark.sql.types._
def bufferFixed(geom: Geometry): Geometry = {
geom.buffer(5.5)
}
sedona.udf.register("udf_bufferFixed", bufferFixed _)
df.selectExpr("udf_bufferFixed(geom)").show()
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.types.DataTypes;
// using lambda function to register the UDF
sparkSession.udf().register(
"udf_bufferFixed",
(UDF1<Geometry, Geometry>) geom ->
geom.buffer(5.5),
new GeometryUDT());
df.selectExpr("udf_bufferFixed(geom)").show()
from sedona.spark import GeometryType
from pyspark.sql.types import DoubleType
def bufferFixed(geom: GeometryType()):
return geom.buffer(5.5)
sedona.udf.register("udf_bufferFixed", bufferFixed, GeometryType())
df.selectExpr("udf_bufferFixed(geom)").show()
Output:
+--------------------------------------------------+
| udf_bufferFixed(geom)|
+--------------------------------------------------+
|POLYGON ((1 -4.5, -0.0729967710887076 -4.394319...|
+--------------------------------------------------+
Geometry, primitive to geometry¶
This UDF example takes a geometry type input and a primitive type input and returns a geometry type output:
import org.locationtech.jts.geom.Geometry
import org.apache.spark.sql.types._
def bufferIt(geom: Geometry, distance: Double): Geometry = {
geom.buffer(distance)
}
sedona.udf.register("udf_buffer", bufferIt _)
df.selectExpr("udf_buffer(geom, distance)").show()
import org.apache.spark.sql.api.java.UDF2;
import org.apache.spark.sql.types.DataTypes;
// using lambda function to register the UDF
sparkSession.udf().register(
"udf_buffer",
(UDF2<Geometry, Double, Geometry>) Geometry::buffer,
new GeometryUDT());
df.selectExpr("udf_buffer(geom, distance)").show()
from sedona.spark import GeometryType
from pyspark.sql.types import DoubleType
def bufferIt(geom: GeometryType(), distance: DoubleType()):
return geom.buffer(distance)
sedona.udf.register("udf_buffer", bufferIt, GeometryType())
df.selectExpr("udf_buffer(geom, distance)").show()
Output:
+--------------------------------------------------+
| udf_buffer(geom, distance)|
+--------------------------------------------------+
|POLYGON ((1 -9, -0.9509032201612866 -8.80785280...|
+--------------------------------------------------+
Geometry, primitive to Geometry, primitive¶
This UDF example takes a geometry type input and a primitive type input and returns a geometry type and a primitive type output:
import org.locationtech.jts.geom.Geometry
import org.apache.spark.sql.types._
import org.apache.spark.sql.api.java.UDF2
val schemaUDF = StructType(Array(
StructField("buffed", GeometryUDT),
StructField("length", DoubleType)
))
val udf_bufferLength = udf(
new UDF2[Geometry, Double, (Geometry, Double)] {
def call(geom: Geometry, distance: Double): (Geometry, Double) = {
val buffed = geom.buffer(distance)
val length = geom.getLength
(buffed, length)
}
}, schemaUDF)
sedona.udf.register("udf_bufferLength", udf_bufferLength)
data.withColumn("bufferLength", expr("udf_bufferLengths(geom, distance)"))
.select("geom", "distance", "bufferLength.*")
.show()
import org.apache.spark.sql.api.java.UDF2;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import scala.Tuple2;
StructType schemaUDF = new StructType()
.add("buffedGeom", new GeometryUDT())
.add("length", DataTypes.DoubleType);
// using lambda function to register the UDF
sparkSession.udf().register("udf_bufferLength",
(UDF2<Geometry, Double, Tuple2<Geometry, Double>>) (geom, distance) -> {
Geometry buffed = geom.buffer(distance);
Double length = buffed.getLength();
return new Tuple2<>(buffed, length);
},
schemaUDF);
df.withColumn("bufferLength", functions.expr("udf_bufferLength(geom, distance)"))
.select("geom", "distance", "bufferLength.*")
.show();
from sedona.spark import GeometryType
from pyspark.sql.types import *
schemaUDF = StructType([
StructField("buffed", GeometryType()),
StructField("length", DoubleType())
])
def bufferAndLength(geom: GeometryType(), distance: DoubleType()):
buffed = geom.buffer(distance)
length = buffed.length
return [buffed, length]
sedona.udf.register("udf_bufferLength", bufferAndLength, schemaUDF)
df.withColumn("bufferLength", expr("udf_bufferLength(geom, buffer)")) \
.select("geom", "buffer", "bufferLength.*") \
.show()
Output:
+------------------------------+--------+--------------------------------------------------+-----------------+
| geom|distance| buffedGeom| length|
+------------------------------+--------+--------------------------------------------------+-----------------+
|POLYGON ((1 1, 1 2, 2 1, 1 1))| 10.0|POLYGON ((1 -9, -0.9509032201612866 -8.80785280...|66.14518337329191|
+------------------------------+--------+--------------------------------------------------+-----------------+
Spatial vectorized udfs (Python only)¶
By default when you create the user defined functions in Python, the UDFs are not vectorized.
This means that the UDFs are called row by row which can be slow.
To speed up the UDFs, you can use the vectorized UDF which will be called in a batch mode
using Apache Arrow.
To create a vectorized UDF please use the decorator sedona_vectorized_udf. Currently supports only the scalar UDFs. Vectorized UDFs are way faster than the normal UDFs. It might be even 2x faster than the normal UDFs.
Note
When you use geometry as an input type, please include the BaseGeometry type, like Point from shapely or geopandas GeoSeries, when you use GEO_SERIES vectorized udf. That's how Sedona infers the type and knows if the data should be cast.
Decorator signature looks as follows:
def sedona_vectorized_udf(
udf_type: SedonaUDFType = SedonaUDFType.SHAPELY_SCALAR, return_type: DataType
): ...
where udf_type is the type of the UDF function, currently supported are:
- SHAPELY_SCALAR
- GEO_SERIES
The main difference is what input data you get in the function Let's analyze the two examples below, that creates buffers from a given geometry.
Shapely scalar UDF¶
import shapely.geometry.base as b
from sedona.spark import sedona_vectorized_udf
@sedona_vectorized_udf(return_type=GeometryType())
def vectorized_buffer(geom: b.BaseGeometry) -> b.BaseGeometry:
return geom.buffer(0.1)
GeoSeries UDF¶
import geopandas as gpd
from sedona.spark import sedona_vectorized_udf, SedonaUDFType
from sedona.spark import GeometryType
@sedona_vectorized_udf(udf_type=SedonaUDFType.GEO_SERIES, return_type=GeometryType())
def vectorized_geo_series_buffer(series: gpd.GeoSeries) -> gpd.GeoSeries:
buffered = series.buffer(0.1)
return buffered
To call the UDFs you can use the following code:
# Shapely scalar UDF
df.withColumn("buffered", vectorized_buffer(df.geom)).show()
# GeoSeries UDF
df.withColumn("buffered", vectorized_geo_series_buffer(df.geom)).show()
Save to permanent storage¶
To save a Spatial DataFrame to some permanent storage such as Hive tables and HDFS, you can simply convert each geometry in the Geometry type column back to a plain String and save the plain DataFrame to wherever you want.
Use the following code to convert the Geometry column in a DataFrame back to a WKT string column:
SELECT ST_AsText(countyshape)
FROM polygondf
Save GeoJSON¶
Since v1.6.1, the GeoJSON data source in Sedona can be used to save a Spatial DataFrame to a single-line JSON file, with geometries written in GeoJSON format.
df.write.format("geojson").save("YOUR/PATH.json")
See this page for more information on writing to GeoJSON.
Save GeoParquet¶
Since v1.3.0, Sedona natively supports writing GeoParquet file. GeoParquet can be saved as follows:
df.write.format("geoparquet").save(geoparquetoutputlocation + "/GeoParquet_File_Name.parquet")
See this page for more information on writing to GeoParquet.
Save to Postgis¶
Unfortunately, the Spark SQL JDBC data source doesn't support creating geometry types in PostGIS using the 'createTableColumnTypes' option. Only the Spark built-in types are recognized. This means that you'll need to manage your PostGIS schema separately from Spark. One way to do this is to create the table with the correct geometry column before writing data to it with Spark. Alternatively, you can write your data to the table using Spark and then manually alter the column to be a geometry type afterward.
Postgis uses EWKB to serialize geometries. If you convert your geometries to EWKB format in Sedona you don't have to do any additional conversion in Postgis.
my_postgis_db# create table my_table (id int8, geom geometry);
df.withColumn("geom", expr("ST_AsEWKB(geom)")
.write.format("jdbc")
.option("truncate","true") // Don't let Spark recreate the table.
// Other options.
.save()
// If you didn't create the table before writing you can change the type afterward.
my_postgis_db# alter table my_table alter column geom type geometry;
Convert between DataFrame and SpatialRDD¶
DataFrame to SpatialRDD¶
Use SedonaSQL DataFrame-RDD Adapter to convert a DataFrame to an SpatialRDD.
var spatialRDD = StructuredAdapter.toSpatialRdd(spatialDf, "usacounty")
SpatialRDD spatialRDD = StructuredAdapter.toSpatialRdd(spatialDf, "usacounty")
from sedona.spark import StructuredAdapter
spatialRDD = StructuredAdapter.toSpatialRdd(spatialDf, "usacounty")
"usacounty" is the name of the geometry column. It is an optional parameter. If you don't provide it, the first geometry column will be used.
SpatialRDD to DataFrame¶
Use SedonaSQL DataFrame-RDD Adapter to convert a DataFrame to an SpatialRDD. Please read Adapter Scaladoc
var spatialDf = StructuredAdapter.toDf(spatialRDD, sedona)
Dataset<Row> spatialDf = StructuredAdapter.toDf(spatialRDD, sedona)
from sedona.spark import StructuredAdapter
spatialDf = StructuredAdapter.toDf(spatialRDD, sedona)
SpatialRDD to DataFrame with spatial partitioning¶
By default, StructuredAdapter.toDf() does not preserve spatial partitions because doing so
may introduce duplicate features for most types of spatial data. These duplicates
are introduced on purpose to ensure correctness when performing a spatial join;
however, when using Sedona to prepare a dataset for distribution this is not typically
desired.
You can use StructuredAdapter and the spatialRDD.spatialPartitioningWithoutDuplicates function to obtain a Sedona DataFrame that is spatially partitioned without duplicates. This is especially useful for generating balanced GeoParquet files while preserving spatial proximity within files, which is crucial for optimizing filter pushdown performance in GeoParquet files.
spatialRDD.spatialPartitioningWithoutDuplicates(GridType.KDBTREE)
// Specify the desired number of partitions as 10, though the actual number may vary
// spatialRDD.spatialPartitioningWithoutDuplicates(GridType.KDBTREE, 10)
var spatialDf = StructuredAdapter.toSpatialPartitionedDf(spatialRDD, sedona)
spatialRDD.spatialPartitioningWithoutDuplicates(GridType.KDBTREE)
// Specify the desired number of partitions as 10, though the actual number may vary
// spatialRDD.spatialPartitioningWithoutDuplicates(GridType.KDBTREE, 10)
Dataset<Row> spatialDf = StructuredAdapter.toSpatialPartitionedDf(spatialRDD, sedona)
from sedona.spark import StructuredAdapter
spatialRDD.spatialPartitioningWithoutDuplicates(GridType.KDBTREE)
# Specify the desired number of partitions as 10, though the actual number may vary
# spatialRDD.spatialPartitioningWithoutDuplicates(GridType.KDBTREE, 10)
spatialDf = StructuredAdapter.toSpatialPartitionedDf(spatialRDD, sedona)
SpatialPairRDD to DataFrame¶
PairRDD is the result of a spatial join query or distance join query. SedonaSQL DataFrame-RDD Adapter can convert the result to a DataFrame. But you need to provide the schema of the left and right RDDs.
var joinResultDf = StructuredAdapter.toDf(joinResultPairRDD, leftDf.schema, rightDf.schema, sedona)
Dataset joinResultDf = StructuredAdapter.toDf(joinResultPairRDD, leftDf.schema, rightDf.schema, sedona);
from sedona.spark import StructuredAdapter
joinResultDf = StructuredAdapter.pairRddToDf(result_pair_rdd, leftDf.schema, rightDf.schema, spark)