Raster SQL app
Note
Sedona uses 1-based indexing for all raster functions except map algebra function, which uses 0-based indexing.
Note
Since v1.5.0, Sedona assumes geographic coordinates to be in longitude/latitude order. If your data is lat/lon order, please use ST_FlipCoordinates to swap X and Y.
Starting from v1.1.0, Sedona SQL supports raster data sources and raster operators in DataFrame and SQL. Raster support is available in all Sedona language bindings including Scala, Java, Python, and R.
This page outlines the steps to manage raster data using SedonaSQL.
var myDataFrame = sedona.sql("YOUR_SQL")
myDataFrame.createOrReplaceTempView("rasterDf")
Dataset<Row> myDataFrame = sedona.sql("YOUR_SQL")
myDataFrame.createOrReplaceTempView("rasterDf")
myDataFrame = sedona.sql("YOUR_SQL")
myDataFrame.createOrReplaceTempView("rasterDf")
Detailed SedonaSQL APIs are available here: SedonaSQL API. You can find example raster data in Sedona GitHub repo.
Set up dependencies¶
- Read Sedona Maven Central coordinates and add Sedona dependencies in build.sbt or pom.xml.
- Add Apache Spark core, Apache SparkSQL in build.sbt or pom.xml.
- Please see SQL example project
- Please read Quick start to install Sedona Python.
- This tutorial is based on Sedona SQL Jupyter Notebook example. You can interact with Sedona Python Jupyter Notebook immediately on Binder. Click
 to interact with Sedona Python Jupyter notebook immediately on Binder.
to interact with Sedona Python Jupyter notebook immediately on Binder.
Create Sedona config¶
Use the following code to create your Sedona config at the beginning. If you already have a SparkSession (usually named spark) created by Wherobots/AWS EMR/Databricks, please skip this step and use spark directly.
Sedona >= 1.4.1
You can add additional Spark runtime config to the config builder. For example, SedonaContext.builder().config("spark.sql.autoBroadcastJoinThreshold", "10485760")
import org.apache.sedona.spark.SedonaContext
val config = SedonaContext.builder()
.master("local[*]") // Delete this if run in cluster mode
.appName("readTestScala") // Change this to a proper name
.getOrCreate()
SedonaContext.builder() to enable Sedona Kryo serializer:
.config("spark.kryo.registrator", classOf[SedonaVizKryoRegistrator].getName) // org.apache.sedona.viz.core.Serde.SedonaVizKryoRegistrator
import org.apache.sedona.spark.SedonaContext;
SparkSession config = SedonaContext.builder()
.master("local[*]") // Delete this if run in cluster mode
.appName("readTestScala") // Change this to a proper name
.getOrCreate()
SedonaContext.builder() to enable Sedona Kryo serializer:
.config("spark.kryo.registrator", SedonaVizKryoRegistrator.class.getName) // org.apache.sedona.viz.core.Serde.SedonaVizKryoRegistrator
from sedona.spark import *
config = SedonaContext.builder() .\
config('spark.jars.packages',
'org.apache.sedona:sedona-spark-shaded-3.0_2.12:1.5.1,'
'org.datasyslab:geotools-wrapper:1.5.1-28.2'). \
getOrCreate()
3.0 in the package name of sedona-spark-shaded with the corresponding major.minor version of Spark, such as sedona-spark-shaded-3.4_2.12:1.5.1.
Sedona < 1.4.1
The following method has been deprecated since Sedona 1.4.1. Please use the method above to create your Sedona config.
var sparkSession = SparkSession.builder()
.master("local[*]") // Delete this if run in cluster mode
.appName("readTestScala") // Change this to a proper name
// Enable Sedona custom Kryo serializer
.config("spark.serializer", classOf[KryoSerializer].getName) // org.apache.spark.serializer.KryoSerializer
.config("spark.kryo.registrator", classOf[SedonaKryoRegistrator].getName)
.getOrCreate() // org.apache.sedona.core.serde.SedonaKryoRegistrator
.config("spark.serializer", classOf[KryoSerializer].getName) // org.apache.spark.serializer.KryoSerializer
.config("spark.kryo.registrator", classOf[SedonaVizKryoRegistrator].getName) // org.apache.sedona.viz.core.Serde.SedonaVizKryoRegistrator
SparkSession sparkSession = SparkSession.builder()
.master("local[*]") // Delete this if run in cluster mode
.appName("readTestScala") // Change this to a proper name
// Enable Sedona custom Kryo serializer
.config("spark.serializer", KryoSerializer.class.getName) // org.apache.spark.serializer.KryoSerializer
.config("spark.kryo.registrator", SedonaKryoRegistrator.class.getName)
.getOrCreate() // org.apache.sedona.core.serde.SedonaKryoRegistrator
.config("spark.serializer", KryoSerializer.class.getName) // org.apache.spark.serializer.KryoSerializer
.config("spark.kryo.registrator", SedonaVizKryoRegistrator.class.getName) // org.apache.sedona.viz.core.Serde.SedonaVizKryoRegistrator
sparkSession = SparkSession. \
builder. \
appName('appName'). \
config("spark.serializer", KryoSerializer.getName). \
config("spark.kryo.registrator", SedonaKryoRegistrator.getName). \
config('spark.jars.packages',
'org.apache.sedona:sedona-spark-shaded-3.0_2.12:1.5.1,'
'org.datasyslab:geotools-wrapper:1.5.1-28.2'). \
getOrCreate()
3.0 in the package name of sedona-spark-shaded with the corresponding major.minor version of Spark, such as sedona-spark-shaded-3.4_2.12:1.5.1.
Initiate SedonaContext¶
Add the following line after creating the Sedona config. If you already have a SparkSession (usually named spark) created by Wherobots/AWS EMR/Databricks, please call SedonaContext.create(spark) instead.
Sedona >= 1.4.1
import org.apache.sedona.spark.SedonaContext
val sedona = SedonaContext.create(config)
import org.apache.sedona.spark.SedonaContext;
SparkSession sedona = SedonaContext.create(config)
from sedona.spark import *
sedona = SedonaContext.create(config)
Sedona < 1.4.1
The following method has been deprecated since Sedona 1.4.1. Please use the method above to create your SedonaContext.
SedonaSQLRegistrator.registerAll(sparkSession)
SedonaSQLRegistrator.registerAll(sparkSession)
from sedona.register import SedonaRegistrator
SedonaRegistrator.registerAll(spark)
You can also register everything by passing --conf spark.sql.extensions=org.apache.sedona.sql.SedonaSqlExtensions to spark-submit or spark-shell.
Load data from files¶
Assume we have a single raster data file called rasterData.tiff, at Path.
Use the following code to load the data and create a raw Dataframe.
var rawDf = sedona.read.format("binaryFile").load(path_to_raster_data)
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
Dataset<Row> rawDf = sedona.read.format("binaryFile").load(path_to_raster_data)
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
rawDf = sedona.read.format("binaryFile").load(path_to_raster_data)
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
The output will look like this:
| path| modificationTime|length| content|
+--------------------+--------------------+------+--------------------+
|file:/Download/ra...|2023-09-06 16:24:...|174803|[49 49 2A 00 08 0...|
For multiple raster data files use the following code to load the data from path and create raw DataFrame.
Note
The above code works too for loading multiple raster data files. if the raster files are in separate directories and the option also makes sure that only .tif or .tiff files are being loaded.
var rawDf = sedona.read.format("binaryFile").option("recursiveFileLookup", "true").option("pathGlobFilter", "*.tif*").load(path_to_raster_data_folder)
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
Dataset<Row> rawDf = sedona.read.format("binaryFile").option("recursiveFileLookup", "true").option("pathGlobFilter", "*.tif*").load(path_to_raster_data_folder);
rawDf.createOrReplaceTempView("rawdf");
rawDf.show();
rawDf = sedona.read.format("binaryFile").option("recursiveFileLookup", "true").option("pathGlobFilter", "*.tif*").load(path_to_raster_data_folder)
rawDf.createOrReplaceTempView("rawdf")
rawDf.show()
The output will look like this:
| path| modificationTime|length| content|
+--------------------+--------------------+------+--------------------+
|file:/Download/ra...|2023-09-06 16:24:...|209199|[4D 4D 00 2A 00 0...|
|file:/Download/ra...|2023-09-06 16:24:...|174803|[49 49 2A 00 08 0...|
|file:/Download/ra...|2023-09-06 16:24:...|174803|[49 49 2A 00 08 0...|
|file:/Download/ra...|2023-09-06 16:24:...| 6619|[49 49 2A 00 08 0...|
The content column in the raster table is still in the raw form, binary form.
Create a Raster type column¶
All raster operations in SedonaSQL require Raster type objects. Therefore, this should be the next step after loading the data.
From Geotiff¶
SELECT RS_FromGeoTiff(content) AS rast, modificationTime, length, path FROM rawdf
To verify this, use the following code to print the schema of the DataFrame:
rasterDf.printSchema()
The output will be like this:
root
|-- rast: raster (nullable = true)
|-- modificationTime: timestamp (nullable = true)
|-- length: long (nullable = true)
|-- path: string (nullable = true)
From Arc Grid¶
The raster data is loaded the same way as tiff file, but the raster data is stored with the extension .asc, ASCII format. The following code creates a Raster type objects from binary data:
SELECT RS_FromArcInfoAsciiGrid(content) AS rast, modificationTime, length, path FROM rawdf
Raster's metadata¶
Sedona has a function to get the metadata for the raster, and also a function to get the world file of the raster.
Metadata¶
This function will return an array of metadata, it will have all the necessary information about the raster, Please refer to RS_MetaData.
SELECT RS_MetaData(rast) FROM rasterDf
Output for the following function will be:
[-1.3095817809482181E7, 4021262.7487925636, 512.0, 517.0, 72.32861272132695, -72.32861272132695, 0.0, 0.0, 3857.0, 1.0]
The first two elements of the array represent the real-world geographic coordinates (like longitude/latitude) of the raster image's top left pixel, while the next two elements represent the pixel dimensions of the raster.
World File¶
There are two kinds of georeferences, GDAL and ESRI seen in world files. For more information please refer to RS_GeoReference.
SELECT RS_GeoReference(rast, "ESRI") FROM rasterDf
The Output will be as follows:
72.328613
0.000000
0.000000
-72.328613
-13095781.645176
4021226.584486
World files are used to georeference and geo-locate images by establishing an image-to-world coordinate transformation that assigns real-world geographic coordinates to the pixels of the image.
Raster Manipulation¶
Since v1.5.0 there have been many additions to manipulate raster data, we will show you a few example queries.
Note
Read SedonaSQL Raster operators to learn how you can use Sedona for raster manipulation.
Coordinate translation¶
Sedona allows you to translate coordinates as per your needs. It can translate pixel locations to world coordinates and vice versa.
PixelAsPoint¶
Use RS_PixelAsPoint to translate pixel coordinates to world location.
SELECT RS_PixelAsPoint(rast, 450, 400) FROM rasterDf
Output:
POINT (-13063342 3992403.75)
World to Raster Coordinate¶
Use RS_WorldToRasterCoord to translate world location to pixel coordinates. To just get X coordinate use RS_WorldToRasterCoordX and for just Y coordinate use RS_WorldToRasterCoordY.
SELECT RS_WorldToRasterCoord(rast, -1.3063342E7, 3992403.75)
Output:
POINT (450 400)
Pixel Manipulation¶
Use RS_Values to fetch values for a specified array of Point Geometries. The coordinates in the point geometry are indicative of real-world location.
SELECT RS_Values(rast, Array(ST_Point(-13063342, 3992403.75), ST_Point(-13074192, 3996020)))
Output:
[132.0, 148.0]
To change values over a grid or area defined by geometry, we will use RS_SetValues.
SELECT RS_SetValues(
rast, 1, 250, 260, 3, 3,
Array(10, 12, 17, 26, 28, 37, 43, 64, 66)
)
Follow the links to get more information on how to use the functions appropriately.
Band Manipulation¶
Sedona provides APIs to select specific bands from a raster image and create a new raster. For example, to select 2 bands from a raster, you can use the RS_Band API to retrieve the desired multi-band raster.
Let's use a multi-band raster for this example. The process of loading and converting it to raster type is the same.
SELECT RS_Band(colorRaster, Array(1, 2))
Let's say you have many single-banded rasters and want to add a band to the raster to perform map algebra operations. You can do so using RS_AddBand Sedona function.
SELECT RS_AddBand(raster1, raster2, 1, 2)
This will result in raster1 having raster2's specified band.
Resample raster data¶
Sedona allows you to resample raster data using different interpolation methods like the nearest neighbor, bilinear, and bicubic to change the cell size or align raster grids, using RS_Resample.
SELECT RS_Resample(rast, 50, -50, -13063342, 3992403.75, true, "bicubic")
For more information please follow the link.
Execute map algebra operations¶
Map algebra is a way to perform raster calculations using mathematical expressions. The expression can be a simple arithmetic operation or a complex combination of multiple operations.
The Normalized Difference Vegetation Index (NDVI) is a simple graphical indicator that can be used to analyze remote sensing measurements from a space platform and assess whether the target being observed contains live green vegetation or not.
NDVI = (NIR - Red) / (NIR + Red)
where NIR is the near-infrared band and Red is the red band.
SELECT RS_MapAlgebra(raster, 'D', 'out = (rast[3] - rast[0]) / (rast[3] + rast[0]);') as ndvi FROM raster_table
For more information please refer to Map Algebra API.
Interoperability between raster and vector data¶
Geometry As Raster¶
Sedona allows you to rasterize a geometry by using RS_AsRaster.
SELECT RS_AsRaster(
ST_GeomFromWKT('POLYGON((150 150, 220 260, 190 300, 300 220, 150 150))'),
RS_MakeEmptyRaster(1, 'b', 4, 6, 1, -1, 1),
'b', 230
)
The image created is as below for the vector:

Note
The vector coordinates are buffed up to showcase the output, the real use case, may or may not match the example.
Spatial range query¶
Sedona provides raster predicates to do a range query using a geometry window, for example, let's use RS_Intersects.
SELECT rast FROM rasterDf WHERE RS_Intersect(rast, ST_GeomFromWKT('POLYGON((0 0, 0 10, 10 10, 10 0, 0 0))'))
Spatial join query¶
Sedona's raster predicates also can do a spatial join using the raster column and geometry column, using the same function as above.
SELECT r.rast, g.geom FROM rasterDf r, geomDf g WHERE RS_Interest(r.rast, g.geom)
Note
These range and join queries will filter rasters using the provided geometric boundary and the spatial boundary of the raster.
Sedona offers more raster predicates to do spatial range queries and spatial join queries. Please refer to raster predicates docs.
Visualize raster images¶
Sedona provides APIs to visualize raster data in an image form.
Base64 String¶
The RS_AsBase64 encodes the raster data as a Base64 string and can be visualized using online decoder.
SELECT RS_AsBase64(rast) FROM rasterDf
HTML Image¶
The RS_AsImage returns an HTML image tag, that can be visualized using an HTML viewer or in Jupyter Notebook. For more information please click on the link.
SELECT RS_AsImage(rast, 500) FROM rasterDf
The output looks like this:
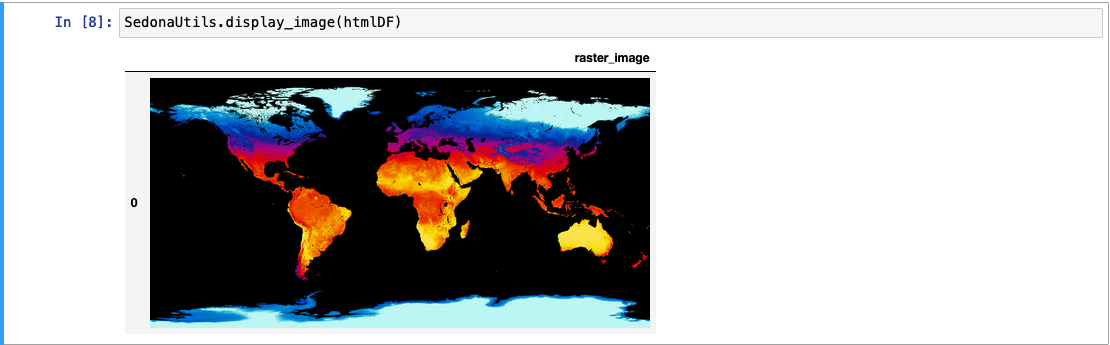
2-D Matrix¶
Sedona offers an API to visualize raster data that is not sufficient for the other APIs mentioned above.
SELECT RS_AsMatrix(rast) FROM rasterDf
Output will be as follows:
| 1 3 4 0|
| 2 9 10 11|
| 3 4 5 6|
Please refer to Raster visualizer docs to learn how to make the most of the visualizing APIs.
Save to permanent storage¶
Sedona has APIs that can save an entire raster column to files in a specified location. Before saving, the raster type column needs to be converted to a binary format. Sedona provides several functions to convert a raster column into a binary column suitable for file storage. Once in binary format, the raster data can then be written to files on disk using the Sedona file storage APIs.
rasterDf.write.format("raster").option("rasterField", "raster").option("fileExtension", ".tiff").mode(SaveMode.Overwrite).save(dirPath)
Sedona has a few writer functions that create the binary DataFrame necessary for saving the raster images.
As Arc Grid¶
Use RS_AsArcGrid to get the binary Dataframe of the raster in Arc Grid format.
SELECT RS_AsArcGrid(raster)
As GeoTiff¶
Use RS_AsGeoTiff to get the binary Dataframe of the raster in GeoTiff format.
SELECT RS_AsGeoTiff(raster)
As PNG¶
Use RS_AsPNG to get the binary Dataframe of the raster in PNG format.
SELECT RS_AsPNG(raster)
Please refer to Raster writer docs for more details.
Collecting raster Dataframes and working with them locally in Python¶
Sedona allows collecting Dataframes with raster columns and working with them locally in Python since v1.6.0.
The raster objects are represented as SedonaRaster objects in Python, which can be used to perform raster operations.
df_raster = sedona.read.format("binaryFile").load("/path/to/raster.tif").selectExpr("RS_FromGeoTiff(content) as rast")
rows = df_raster.collect()
raster = rows[0].rast
raster # <sedona.raster.sedona_raster.InDbSedonaRaster at 0x1618fb1f0>
You can retrieve the metadata of the raster by accessing the properties of the SedonaRaster object.
raster.width # width of the raster
raster.height # height of the raster
raster.affine_trans # affine transformation matrix
raster.crs_wkt # coordinate reference system as WKT
You can get a numpy array containing the band data of the raster using the as_numpy or as_numpy_masked method. The
band data is organized in CHW order.
raster.as_numpy() # numpy array of the raster
raster.as_numpy_masked() # numpy array with nodata values masked as nan
If you want to work with the raster data using rasterio, you can retrieve a rasterio.DatasetReader object using the
as_rasterio method.
ds = raster.as_rasterio() # rasterio.DatasetReader object
# Work with the raster using rasterio
band1 = ds.read(1) # read the first band
Writing Python UDF to work with raster data¶
You can write Python UDFs to work with raster data in Python. The UDFs can take SedonaRaster objects as input and
return any Spark data type as output. This is an example of a Python UDF that calculates the mean of the raster data.
from pyspark.sql.types import DoubleType
def mean_udf(raster):
return float(raster.as_numpy().mean())
sedona.udf.register("mean_udf", mean_udf, DoubleType())
df_raster.withColumn("mean", expr("mean_udf(rast)")).show()
+--------------------+------------------+
| rast| mean|
+--------------------+------------------+
|GridCoverage2D["g...|1542.8092886117788|
+--------------------+------------------+
It is much trickier to write an UDF that returns a raster object, since Sedona does not support serializing Python raster
objects yet. However, you can write a UDF that returns the band data as an array and then construct the raster object using
RS_MakeRaster. This is an example of a Python UDF that creates a mask raster based on the first band of the input raster.
from pyspark.sql.types import ArrayType, DoubleType
import numpy as np
def mask_udf(raster):
band1 = raster.as_numpy()[0,:,:]
mask = (band1 < 1400).astype(np.float64)
return mask.flatten().tolist()
sedona.udf.register("mask_udf", band_udf, ArrayType(DoubleType()))
df_raster.withColumn("mask", expr("mask_udf(rast)")).withColumn("mask_rast", expr("RS_MakeRaster(rast, 'I', mask)")).show()
+--------------------+--------------------+--------------------+
| rast| mask| mask_rast|
+--------------------+--------------------+--------------------+
|GridCoverage2D["g...|[0.0, 0.0, 0.0, 0...|GridCoverage2D["g...|
+--------------------+--------------------+--------------------+
Performance optimization¶
When working with large raster datasets, refer to the documentation on storing raster geometries in Parquet format for recommendations to optimize performance.