单节点结果
本页面展示了 SpatialBench 在 SedonaDB、DuckDB 与 GeoPandas 上的单节点基准测试结果。该基准测试于 2025 年 9 月 22 日进行,所使用的版本为 SpatialBench v0.1.0 预发布版本(main 分支上的提交 9094be8)。
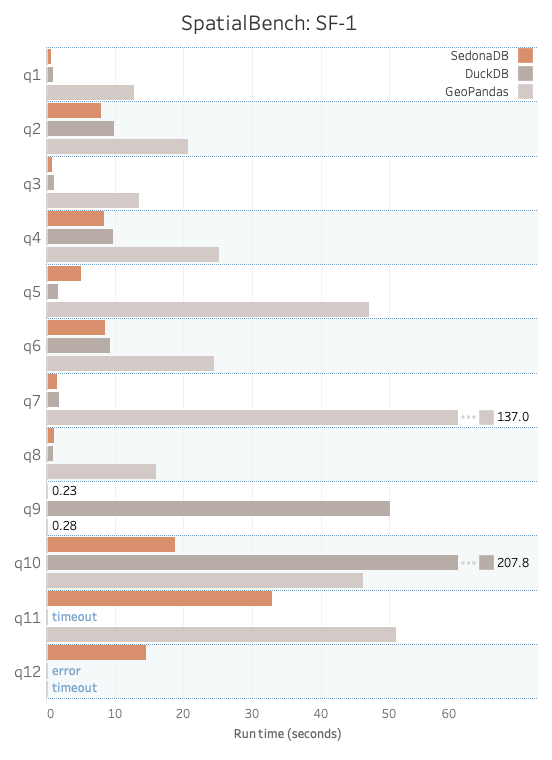
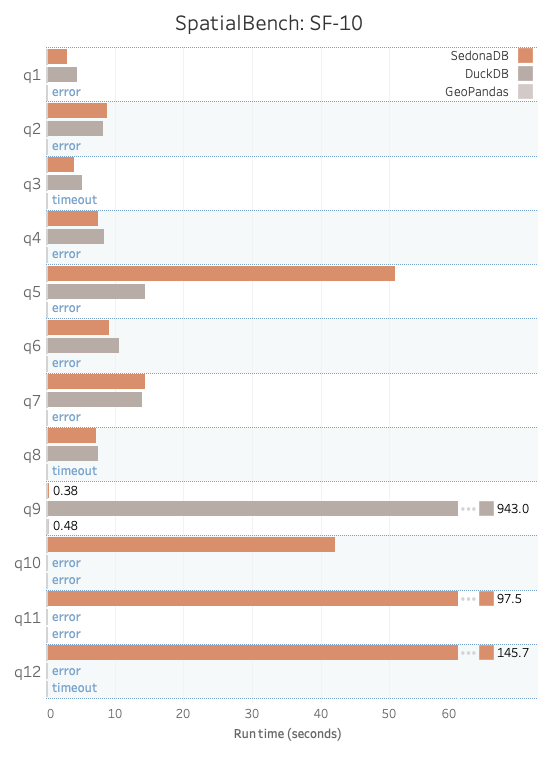
下面是 SpatialBench v0.1 在规模因子 1(SF1)和规模因子 10(SF10)下对查询 1–12 的运行结果。
硬件¶
该基准测试运行在 AWS EC2 m7i.2xlarge 实例上,配备 8 个 CPU 和 32 GB 内存。我们鼓励你尝试在不同的硬件配置上运行 SpatialBench,并与社区分享你的结果。
测试数据¶
数据集由 SpatialBench 的 dbgen 生成,并以纯 Parquet 格式存储在 AWS S3 存储桶中。几何列以 Well-Known Binary(WKB)编码存储,使用 Parquet 的 BINARY 类型。所有系统都直接从 S3 桶中读取 Parquet 文件,未涉及任何本地预加载。每个 Parquet row group 的大小为 128 MB。为了更贴近真实场景,大型 Parquet 文件会被拆分为多个较小的文件,每个约 200–300 MB。
我们在 us-west-2 区域提供规模因子为 1 和 10 的公开数据集。你可以通过以下路径访问:
s3://wherobots-examples/data/spatialbench/SpatialBench_sf1/building/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf1/customer/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf1/driver/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf1/trip/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf1/vehicle/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf1/zone/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf10/building/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf10/customer/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf10/driver/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf10/trip/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf10/vehicle/
s3://wherobots-examples/data/spatialbench/SpatialBench_sf10/zone/
软件¶
本基准测试使用以下软件版本:
- GeoPandas: 1.1.1
- Shapely: 2.1.1
- NumPy: 2.3.3
- DuckDB: 1.4.0
- SedonaDB: 0.1.0
本基准测试报告明确给出软件版本,便于追踪性能随时间的变化。除非另行说明,所有软件均使用默认设置。对于 DuckDB,我们显式将 enable_external_file_cache 设置为 false,以与其他引擎保持一致,重点关注冷启动查询的运行时间。
所记录的运行时间涵盖了每个引擎的整个查询执行过程,包括数据加载。我们对每个查询结果使用 COUNT 来触发完整执行,但没有将结果写入外部文件,以避免引入额外的写入开销。每个查询的超时阈值设为 1200 秒。
由于 GeoPandas 是单线程执行且缺乏查询优化器,任何并行化或优化都必须手动实现。在本基准测试中,我们采用与其他引擎运行的 SQL 查询相对应的直接 Python 实现。如果你是 GeoPandas 专家,欢迎与我们合作完成更优化或更并行化的版本。
结果分析¶
空间过滤与基础操作(Q1–Q6)¶
DuckDB 和 SedonaDB 在 SF 1 和 SF 10 下均能达到类似的低延迟表现,而 GeoPandas 在更大规模时则力不从心。主要原因是 GeoPandas 缺乏查询优化器来选择高效的执行策略,且没有多核并行能力。相比之下,DuckDB 和 SedonaDB 利用列式数据布局、向量化执行、多核并行以及查询优化等技术,实现了较强的性能。不过,SedonaDB 在空间聚合(Q5)上仍存在挑战,DuckDB 在该项上表现明显更好。这是 SedonaDB 的一个已知问题,已列入改进计划。
几何计算(Q7–Q9)¶
在交集/IoU(Q9)方面,SedonaDB 表现尤为出色,效率提升显著。这类查询主要关注面积计算、距离计算和空间相交等几何操作。
复杂空间连接与聚合(Q10–Q11)¶
在更重的连接负载(特别是 Q10 和 Q11)上,SedonaDB 一直表现强劲,这得益于它的自适应空间连接策略——可基于空间统计为每个分区选择最合适的算法。DuckDB 在某些连接查询上表现良好,但在特定情形下会遇到扩展性问题;GeoPandas 能完成 SF 1,但无法完成 SF 10。
最近邻连接(Q12)¶
SedonaDB 在 SF 1 和 SF 10 下均能完成 KNN 连接,这得益于其原生算子和优化算法。相比之下,DuckDB 和 GeoPandas 目前都没有内置的 KNN 连接支持。对于这些引擎,我们必须手工编写额外的代码,效率明显较低。未来若增加原生 KNN 能力,将有望帮助这两个引擎缩小这一差距。
综合表现¶
SedonaDB 在所有类型的查询上均表现均衡,并能有效扩展到 SF 10。DuckDB 在空间过滤和部分几何计算上表现出色,但在复杂连接和 KNN 查询上存在挑战。GeoPandas 虽在 Python 生态中广受欢迎,但需要手动优化和并行化才能有效处理较大规模的数据集。
自动化基准测试(GitHub Actions)¶
我们在每次 Pull Request 时以及定期通过 GitHub Actions 运行自动化基准测试,以验证所有 SpatialBench 查询都能在受支持的引擎上完整运行。
不适合用于性能对比
GitHub Actions 上的基准测试旨在验证查询的正确性和可运行性,**不适用于**严肃的性能对比。GitHub Actions 运行器的性能存在波动,且资源有限。如需进行有意义的性能基准测试,请按上述章节的描述,使用合适的规模因子在专用硬件上运行 SpatialBench。
查看最新结果¶
访问 GitHub Actions 基准测试页面,可查看最新结果。点击任一成功的工作流运行记录,并向下滚动至 Summary 部分,即可查看:
- 各引擎的查询执行状态
- 所有 12 个查询的对比情况
- 错误与超时信息
支持的引擎¶
自动化测试覆盖以下引擎:
- 🦆 DuckDB —— 进程内分析型数据库,带有空间扩展
- 🐼 GeoPandas —— Python 地理空间数据分析库
- 🌵 SedonaDB —— 高性能空间分析引擎
- 🐻❄️ Spatial Polars —— Polars 数据帧的地理空间扩展
运行你自己的基准测试¶
你可以从 Actions 标签页 手动触发自动化测试,并可配置以下选项:
- 规模因子:0.1、1 或 10
- 引擎:选择参与测试的引擎
- 查询超时:为较长查询调整超时阈值(默认:60 秒)
- 每个查询的运行次数:1、3 或 5 次(用于求平均,默认为 3)
- 依赖包版本:固定特定版本或使用最新版本
基准测试代码¶
你可以在 sedona-spatialbench GitHub 仓库中获取并运行基准测试代码。
你可以在本地以及云环境中生成数据集并运行基准测试。
该仓库包含一个 issue 追踪器,你可以在那里提交 bug 报告或建议代码改进。
原始基准测试性能数据¶
下表给出了详细的基准测试结果。所有时间单位均为秒。ERROR 表示软件因异常(例如内存不足)未能完成查询。TIMEOUT 表示查询运行超过 1200 秒仍未返回结果。
| 查询 | SedonaDB | DuckDB | GeoPandas |
|---|---|---|---|
| q1 | 0.66 | 0.96 | 12.78 |
| q2 | 8.07 | 9.95 | 20.74 |
| q3 | 0.80 | 1.17 | 13.59 |
| q4 | 8.41 | 9.83 | 25.24 |
| q5 | 5.10 | 1.80 | 47.08 |
| q6 | 8.59 | 9.36 | 24.43 |
| q7 | 1.66 | 1.82 | 137.00 |
| q8 | 1.10 | 1.08 | 16.08 |
| q9 | 0.23 | 50.15 | 0.28 |
| q10 | 18.79 | 207.84 | 46.13 |
| q11 | 32.98 | TIMEOUT | 51.01 |
| q12 | 14.55 | ERROR | TIMEOUT |
| 查询 | SedonaDB | DuckDB | GeoPandas |
|---|---|---|---|
| q1 | 3.04 | 4.58 | ERROR |
| q2 | 8.89 | 8.26 | ERROR |
| q3 | 4.09 | 5.17 | TIMEOUT |
| q4 | 7.52 | 8.51 | ERROR |
| q5 | 50.81 | 14.40 | ERROR |
| q6 | 9.11 | 10.67 | ERROR |
| q7 | 14.44 | 14.03 | ERROR |
| q8 | 7.24 | 7.57 | TIMEOUT |
| q9 | 0.38 | 942.98 | 0.49 |
| q10 | 42.02 | ERROR | ERROR |
| q11 | 97.52 | ERROR | ERROR |
| q12 | 145.66 | ERROR | TIMEOUT |
未来工作¶
我们计划在未来工作中加入更多的引擎和数据库,例如:
dask-geopandas,用于在单节点的多核之间实现并行化- 一个 R 语言的地理空间引擎
如果你是上述任何技术的专家,欢迎主导该项目或与我们联系开展合作。
为了保持清晰和简洁,专为多节点环境设计的计算引擎被有意地排除在这些单节点结果之外。同样,像 PostGIS 这样的事务型数据库,其查询执行方式与纯 Python 引擎(如 GeoPandas)或分析型引擎(如 SedonaDB、DuckDB)有本质区别。由于 SpatialBench 主要聚焦于分析型工作负载,这些系统在当前研究中并未包含。
SpatialBench 倡议的总体目标,是为空间领域社区提供一套可靠的基准测试,并帮助推动更好的用户工具的快速发展。