SpatialBench 数据集与生成器¶
本页面介绍 SpatialBench 数据集,并演示如何使用生成器来生成相应的空间数据表。
SpatialBench 是一个面向地理空间的基准测试套件,用于评估和优化数据系统中的空间查询性能。它借鉴了星型模式基准测试(SSB)和纽约市出租车与豪华轿车委员会(NYC TLC)数据集的设计思想,将真实的城市出行场景与标准化的基准测试方法相结合。
SpatialBench 采用了 SSB 中常见的星型模式结构,并在此基础上增加了空间属性,如上车点和下车点、区域的空间多边形边界以及建筑物轮廓。这些空间扩展使 SpatialBench 能够有效测试包括空间连接、基于距离的查询、空间聚合、以及点在多边形内分析在内的地理空间操作。
通过结合 SSB 的系统性方法与源自 NYC TLC 数据的真实场景,SpatialBench 提供了与城市出行和空间分析工作负载高度相关的、具有实际意义的基准测试。
数据模型¶
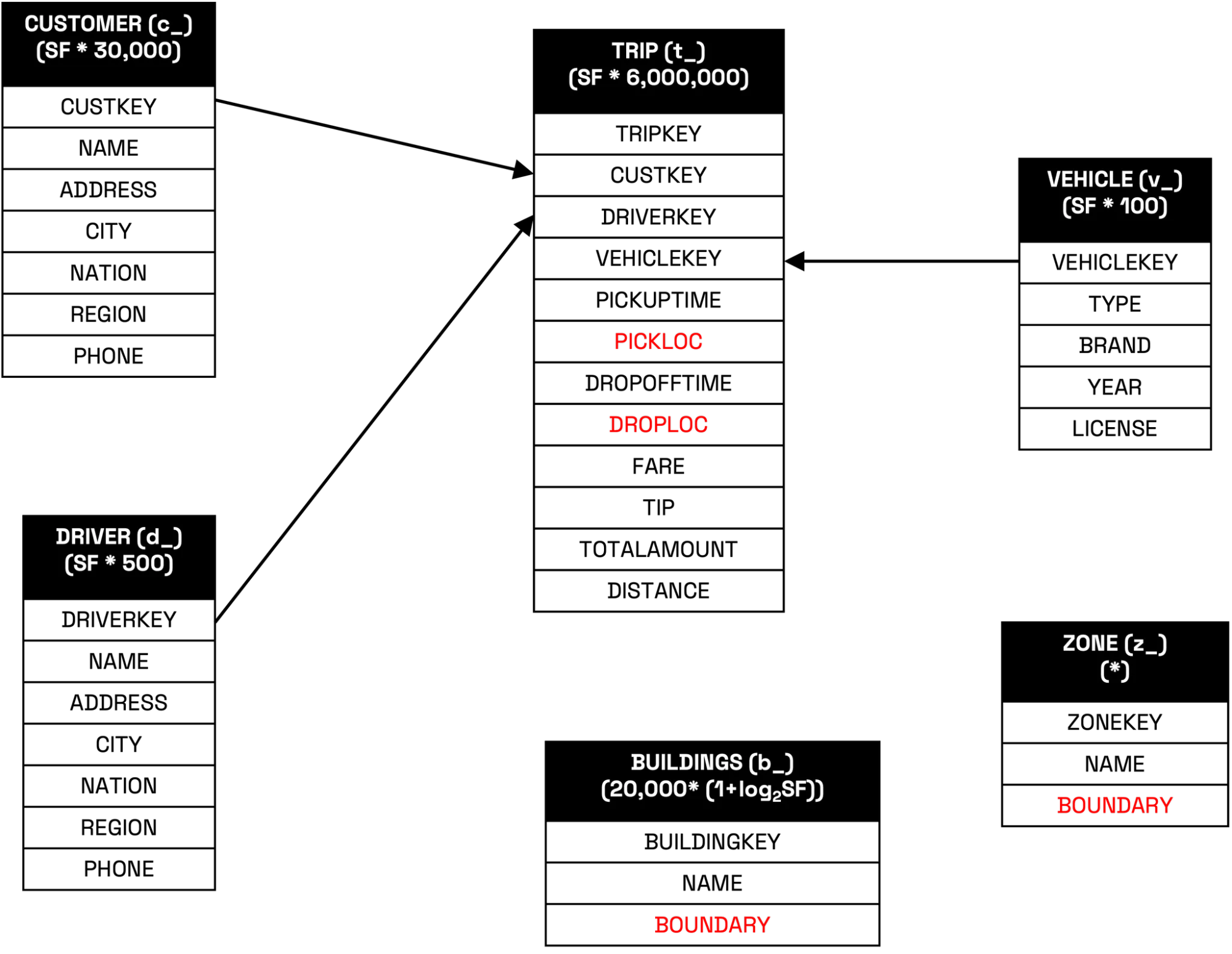
SpatialBench 包含以下表:
- Trip(事实表):记录每一次行程,包含空间属性(上车点和下车点)、行程费用、距离、时长,以及上车时间和下车时间。
- Customer:表示预订行程的客户。
- Driver:表示完成行程的司机。
- Vehicle:行程使用车辆的详细信息。
- Zone:表示城市区域或行政分区的多边形边界。
- Building:表示建筑物位置、类型和名称的多边形轮廓。
| 表名 | 类型 | 缩写前缀 | 主要作用 | 空间属性 | 每个规模因子(SF)下的大小 |
|---|---|---|---|---|---|
| Building | 维度表 | b_ | 表示建筑物位置的多边形轮廓 | 多边形轮廓 | 20K × (1 + log₂(SF)) |
| Customer | 维度表 | c_ | 表示客户 | 无 | 30K × SF |
| Driver | 维度表 | s_ | 表示司机 | 无 | 500 × SF |
| Trip | 事实表 | t_ | 记录每次行程 | 上车点 / 下车点(坐标) | 6M × SF |
| Vehicle | 维度表 | v_ | 车辆详情 | 无 | 100 × SF |
| Zone | 维度表 | z_ | 城市区域的多边形边界 | 多边形边界 | 按 SF 范围分级(详见下表) |
Zone 表的扩展规则¶
| 规模因子(SF) | 包含的 Zone 子类型 | Zone 数量 |
|---|---|---|
| [0, 10) | microhood、macrohood、county | 156,095 |
| [10, 100) | + neighborhood | 455,711 |
| [100, 1000) | + localadmin、locality、region、dependency | 1,035,371 |
| [1000+) | + country | 1,035,749 |
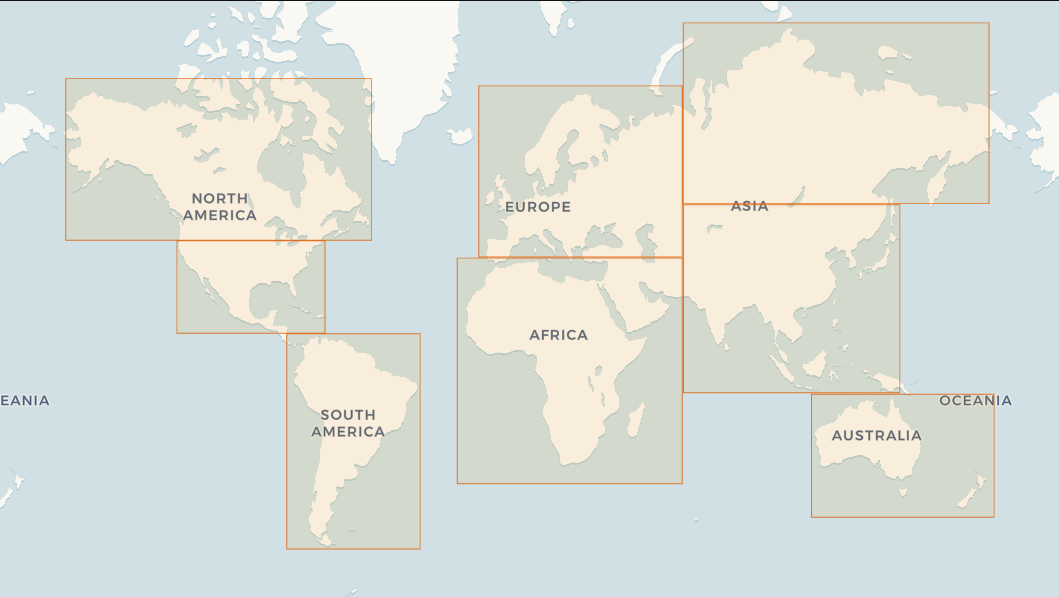
地理覆盖范围¶
SpatialBench 的数据生成器使用按大洲划分的仿射变换。每个大洲都有一个边界多边形定义,确保生成的数据大多落在陆地上,并自然引入真实地理分布所固有的偏斜。
边界多边形如下:
| 区域 | 边界多边形 |
|---|---|
| 非洲 | POLYGON ((-20.062752 -40.044425, 64.131567 -40.044425, 64.131567 37.579421, -20.062752 37.579421, -20.062752 -40.044425)) |
| 欧洲 | POLYGON ((-11.964479 37.926872, 64.144374 37.926872, 64.144374 71.82884, -11.964479 71.82884, -11.964479 37.926872)) |
| 南亚 | POLYGON ((64.58354 -9.709049, 145.526096 -9.709049, 145.526096 51.672557, 64.58354 51.672557, 64.58354 -9.709049)) |
| 北亚 | POLYGON ((64.495655 51.944267, 178.834704 51.944267, 178.834704 77.897255, 64.495655 77.897255, 64.495655 51.944267)) |
| 大洋洲 | POLYGON ((112.481901 -48.980212, 180.768942 -48.980212, 180.768942 -10.228433, 112.481901 -10.228433, 112.481901 -48.980212)) |
| 南美洲 | POLYGON ((-83.833822 -56.170016, -33.904338 -56.170016, -33.904338 12.211188, -83.833822 12.211188, -83.833822 -56.170016)) |
| 北美洲南部 | POLYGON ((-124.890724 12.382931, -69.511192 12.382931, -69.511192 42.55308, -124.890724 42.55308, -124.890724 12.382931)) |
| 北美洲北部 | POLYGON ((-166.478008 42.681087, -52.053245 42.681087, -52.053245 72.659041, -166.478008 72.659041, -166.478008 42.681087)) |
分布选项¶
默认情况下,SpatialBench 在生成 trip 表和 building 表时,会使用按大洲划分的仿射变换,并配合层次化 Thomas 分布(Hierarchical Thomas)生成点。
为了让数据更贴近真实情况,你可以在生成表时从多种空间分布中进行选择:
- Uniform(均匀分布):在单位正方形内均匀分布点。
- Normal(正态分布):围绕均值的高斯分布,方差可配置。
- Diagonal(对角线分布):点集中分布在 y=x 对角线附近,可配置缓冲区。
- Bit(比特分布):由概率和位数控制的递归类网格图案。
- Sierpinski(谢尔宾斯基分布):自相似分形图案,覆盖呈高度偏斜。
- Thomas:带有真实热点和长尾偏斜的聚类分布。
- Hierarchical Thomas(层次化 Thomas):多级聚类(城市 → 街区 → 点),适合模拟城市人口聚集的模式。
这些选项可以让你根据自己的基准测试需求来调整空间偏斜度。
要详细了解 SpatialBench 支持的空间分布、控制这些分布的参数以及它们对数据的影响,请参见 SpatialBench 数据分布 页面。
数据生成器¶
可以使用以下命令为规模因子 1(SF1)生成所有表:
spatialbench-cli -s 1 --format=parquet --output-dir sf1-parquet
你也可以通过提供 S3 URI 将数据直接生成到 Amazon S3:
spatialbench-cli -s 1 --format=parquet --output-dir s3://my-bucket/sf1-parquet
关于 AWS 凭据的配置,请参见快速开始。
sf1-parquet 目录内会包含以下文件:
building.parquetcustomer.parquetdriver.parquettrip.parquetvehicle.parquetzone.parquet
SpatialBench 数据生成器的完整使用说明,请参见 README。
数据大小¶
下表给出了在不同规模因子下,各表未压缩的 Parquet 文件大小:
| 类别 | SF1 | SF10 | SF100 | SF1000 |
|---|---|---|---|---|
| Zone | 1.3 GB | 2.0 GB | 5.4 GB | 5.7 GB |
| Trip | 471.1 MB | 5.0 GB | 50.4 GB | 512.7 GB |
| Building | 2.4 MB | 10.2 MB | 18.0 MB | 0.03 GB |
| Customer | 2.5 MB | 23.1 MB | 227.1 MB | 2.2 GB |
| Driver | 0.04 MB | 0.4 MB | 4.0 MB | 0.03 GB |
| Vehicle | 0.01 MB | 0.03 MB | 0.3 MB | 0.003 GB |
| 合计 | 1.8 GB | 7.0 GB | 56.0 GB | 520.6 GB |