
Apache Sedona™ (incubating) is a cluster computing system for processing large-scale spatial data. Sedona extends existing cluster computing systems, such as Apache Spark and Apache Flink, with a set of out-of-the-box distributed Spatial Datasets and Spatial SQL that efficiently load, process, and analyze large-scale spatial data across machines.
Set up Scala and Java API in 5 minutes with Maven and SBT.
Python and R API are also available on PyPi and CRAN.
Get started Go to GitHubSystem Architecture

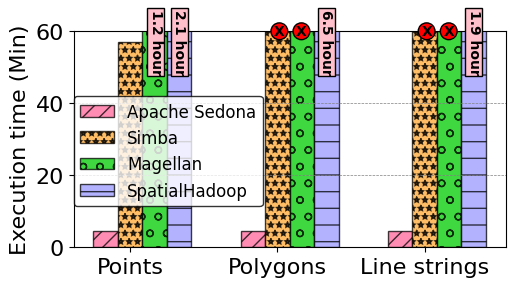
High Speed
According to our benchmark and third-party research papers, Sedona runs 2X - 10X faster than other Spark-based geospatial data systems on computation-intensive query workloads.
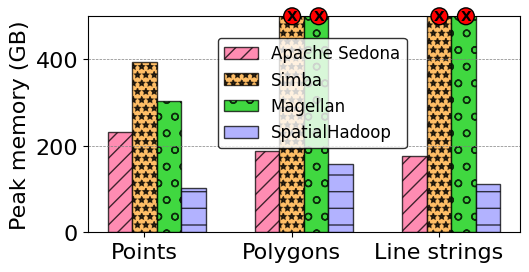
Low Memory Consumption
According to our benchmark and third-party research papers, Sedona has 50% less peak memory consumption than other Spark-based geospatial data systems for large-scale in-memory query processing.
Ease of Use
Sedona offers Scala, Java, Spatial SQL, Python, and R APIs and integrates them into underlying system kernels with care. You can simply create spatial analytics and data mining applications and run them in any cloud environments.
SELECT superhero.name
FROM city, superhero
WHERE ST_Contains(city.geom, superhero.geom)
AND city.name = 'Gotham'