Spatial SQL Application in Python¶
Introduction¶
This package is an extension to Apache Spark SQL package. It allow to use spatial functions on dataframes.
SedonaSQL supports SQL/MM Part3 Spatial SQL Standard. It includes four kinds of SQL operators as follows. All these operators can be directly called through:
spark.sql("YOUR_SQL")
Note
This tutorial is based on Sedona SQL Jupyter Notebook example. You can interact with Sedona Python Jupyter notebook immediately on Binder. Click ![]() and wait for a few minutes. Then select a notebook and enjoy!
and wait for a few minutes. Then select a notebook and enjoy!
Installation¶
Please read Quick start to install Sedona Python.
Register package¶
Before writing any code with Sedona please use the following code.
from sedona.register import SedonaRegistrator
SedonaRegistrator.registerAll(spark)
You can also register functions by passing --conf spark.sql.extensions=org.apache.sedona.sql.SedonaSqlExtensions to spark-submit or spark-shell.
Writing Application¶
Use KryoSerializer.getName and SedonaKryoRegistrator.getName class properties to reduce memory impact.
spark = SparkSession.\
builder.\
master("local[*]").\
appName("Sedona App").\
config("spark.serializer", KryoSerializer.getName).\
config("spark.kryo.registrator", SedonaKryoRegistrator.getName) .\
getOrCreate()
To turn on SedonaSQL function inside pyspark code use SedonaRegistrator.registerAll method on existing pyspark.sql.SparkSession instance ex.
SedonaRegistrator.registerAll(spark)
After that all the functions from SedonaSQL are available, moreover using collect or toPandas methods on Spark DataFrame returns Shapely BaseGeometry objects.
Based on GeoPandas DataFrame,
Pandas DataFrame with shapely objects or Sequence with
shapely objects, Spark DataFrame can be created using
spark.createDataFrame method. To specify Schema with
geometry inside please use GeometryType() instance
(look at examples section to see that in practice).
Examples¶
SedonaSQL¶
All SedonaSQL functions (list depends on SedonaSQL version) are available in Python API. For details please refer to API/SedonaSQL page.
For example use SedonaSQL for Spatial Join.
counties = spark.\
read.\
option("delimiter", "|").\
option("header", "true").\
csv("counties.csv")
counties.createOrReplaceTempView("county")
counties_geom = spark.sql(
"SELECT county_code, st_geomFromWKT(geom) as geometry from county"
)
counties_geom.show(5)
+-----------+--------------------+
|county_code| geometry|
+-----------+--------------------+
| 1815|POLYGON ((21.6942...|
| 1410|POLYGON ((22.7238...|
| 1418|POLYGON ((21.1100...|
| 1425|POLYGON ((20.9891...|
| 1427|POLYGON ((19.5087...|
+-----------+--------------------+
import geopandas as gpd
points = gpd.read_file("gis_osm_pois_free_1.shp")
points_geom = spark.createDataFrame(
points[["fclass", "geometry"]]
)
points_geom.show(5, False)
+---------+-----------------------------+
|fclass |geometry |
+---------+-----------------------------+
|camp_site|POINT (15.3393145 52.3504247)|
|chalet |POINT (14.8709625 52.691693) |
|motel |POINT (15.0946636 52.3130396)|
|atm |POINT (15.0732014 52.3141083)|
|hotel |POINT (15.0696777 52.3143013)|
+---------+-----------------------------+
points_geom.createOrReplaceTempView("pois")
counties_geom.createOrReplaceTempView("counties")
spatial_join_result = spark.sql(
"""
SELECT c.county_code, p.fclass
FROM pois AS p, counties AS c
WHERE ST_Intersects(p.geometry, c.geometry)
"""
)
spatial_join_result.explain()
== Physical Plan ==
*(2) Project [county_code#230, fclass#239]
+- RangeJoin geometry#240: geometry, geometry#236: geometry, true
:- Scan ExistingRDD[fclass#239,geometry#240]
+- Project [county_code#230, st_geomfromwkt(geom#232) AS geometry#236]
+- *(1) FileScan csv [county_code#230,geom#232] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/projects/sedona/counties.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<county_code:string,geom:string>
pois_per_county = spatial_join_result.groupBy("county_code", "fclass"). \
count()
pois_per_county.show(5, False)
+-----------+---------+-----+
|county_code|fclass |count|
+-----------+---------+-----+
|0805 |atm |6 |
|0805 |bench |75 |
|0803 |museum |9 |
|0802 |fast_food|5 |
|0862 |atm |20 |
+-----------+---------+-----+
Integration with GeoPandas and Shapely¶
sedona has implemented serializers and deserializers which allows to convert Sedona Geometry objects into Shapely BaseGeometry objects. Based on that it is possible to load the data with geopandas from file (look at Fiona possible drivers) and create Spark DataFrame based on GeoDataFrame object.
Example, loading the data from shapefile using geopandas read_file method and create Spark DataFrame based on GeoDataFrame:
import geopandas as gpd
from pyspark.sql import SparkSession
from sedona.register import SedonaRegistrator
spark = SparkSession.builder.\
getOrCreate()
SedonaRegistrator.registerAll(spark)
gdf = gpd.read_file("gis_osm_pois_free_1.shp")
spark.createDataFrame(
gdf
).show()
+---------+----+-----------+--------------------+--------------------+
| osm_id|code| fclass| name| geometry|
+---------+----+-----------+--------------------+--------------------+
| 26860257|2422| camp_site| de Kroon|POINT (15.3393145...|
| 26860294|2406| chalet| Leśne Ustronie|POINT (14.8709625...|
| 29947493|2402| motel| null|POINT (15.0946636...|
| 29947498|2602| atm| null|POINT (15.0732014...|
| 29947499|2401| hotel| null|POINT (15.0696777...|
| 29947505|2401| hotel| null|POINT (15.0155749...|
+---------+----+-----------+--------------------+--------------------+
Reading data with Spark and converting to GeoPandas
import geopandas as gpd
from pyspark.sql import SparkSession
from sedona.register import SedonaRegistrator
spark = SparkSession.builder.\
getOrCreate()
SedonaRegistrator.registerAll(spark)
counties = spark.\
read.\
option("delimiter", "|").\
option("header", "true").\
csv("counties.csv")
counties.createOrReplaceTempView("county")
counties_geom = spark.sql(
"SELECT *, st_geomFromWKT(geom) as geometry from county"
)
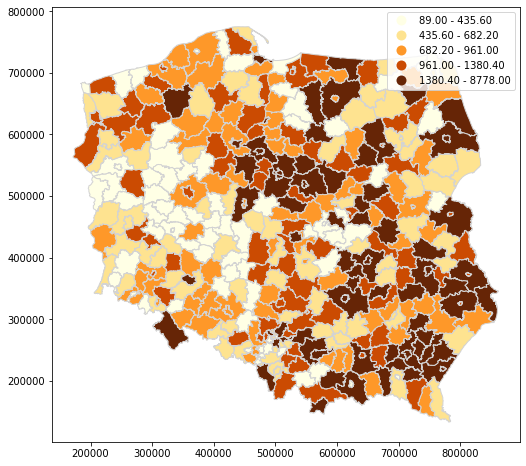
df = counties_geom.toPandas()
gdf = gpd.GeoDataFrame(df, geometry="geometry")
gdf.plot(
figsize=(10, 8),
column="value",
legend=True,
cmap='YlOrBr',
scheme='quantiles',
edgecolor='lightgray'
)
DataFrame Style API¶
Sedona functions can be called used a DataFrame style API similar to PySpark's own functions.
The functions are spread across four different modules: sedona.sql.st_constructors, sedona.sql.st_functions, sedona.sql.st_predicates, and sedona.sql.st_aggregates.
All of the functions can take columns or strings as arguments and will return a column representing the sedona function call.
This makes them integratable with DataFrame.select, DataFrame.join, and all of the PySpark functions found in the pyspark.sql.functions module.
As an example of the flexibility:
from pyspark.sql import functions as f
from sedona.sql import st_constructors as stc
df = spark.sql("SELECT array(0.0, 1.0, 2.0) AS values")
min_value = f.array_min("values")
max_value = f.array_max("values")
df = df.select(stc.ST_Point(min_value, max_value).alias("point"))
The above code will generate the following dataframe:
+-----------+
|point |
+-----------+
|POINT (0 2)|
+-----------+
Some functions will take native python values and infer them as literals. For example:
df = df.select(stc.ST_Point(1.0, 3.0).alias("point"))
This will generate a dataframe with a constant point in a column:
+-----------+
|point |
+-----------+
|POINT (1 3)|
+-----------+
For a description of what values a function may take please refer to their specific docstrings.
The following rules are followed when passing values to the sedona functions:
1. Column type arguments are passed straight through and are always accepted.
1. str type arguments are always assumed to be names of columns and are wrapped in a Column to support that.
If an actual string literal needs to be passed then it will need to be wrapped in a Column using pyspark.sql.functions.lit.
1. Any other types of arguments are checked on a per function basis.
Generally, arguments that could reasonably support a python native type are accepted and passed through.
Check the specific docstring of the function to be sure.
1. Shapely Geometry objects are not currently accepted in any of the functions.
Creating Spark DataFrame based on shapely objects¶
Supported Shapely objects¶
| shapely object | Available |
|---|---|
| Point |  |
| MultiPoint | |
| LineString | |
| MultiLinestring | |
| Polygon | |
| MultiPolygon | |
To create Spark DataFrame based on mentioned Geometry types, please use GeometryType from sedona.sql.types module. Converting works for list or tuple with shapely objects.
Schema for target table with integer id and geometry type can be defined as follow:
from pyspark.sql.types import IntegerType, StructField, StructType
from sedona.sql.types import GeometryType
schema = StructType(
[
StructField("id", IntegerType(), False),
StructField("geom", GeometryType(), False)
]
)
Also Spark DataFrame with geometry type can be converted to list of shapely objects with collect method.
Example usage for Shapely objects¶
Point¶
from shapely.geometry import Point
data = [
[1, Point(21.0, 52.0)],
[1, Point(23.0, 42.0)],
[1, Point(26.0, 32.0)]
]
gdf = spark.createDataFrame(
data,
schema
)
gdf.show()
+---+-------------+
| id| geom|
+---+-------------+
| 1|POINT (21 52)|
| 1|POINT (23 42)|
| 1|POINT (26 32)|
+---+-------------+
gdf.printSchema()
root
|-- id: integer (nullable = false)
|-- geom: geometry (nullable = false)
MultiPoint¶
from shapely.geometry import MultiPoint
data = [
[1, MultiPoint([[19.511463, 51.765158], [19.446408, 51.779752]])]
]
gdf = spark.createDataFrame(
data,
schema
).show(1, False)
+---+---------------------------------------------------------+
|id |geom |
+---+---------------------------------------------------------+
|1 |MULTIPOINT ((19.511463 51.765158), (19.446408 51.779752))|
+---+---------------------------------------------------------+
LineString¶
from shapely.geometry import LineString
line = [(40, 40), (30, 30), (40, 20), (30, 10)]
data = [
[1, LineString(line)]
]
gdf = spark.createDataFrame(
data,
schema
)
gdf.show(1, False)
+---+--------------------------------+
|id |geom |
+---+--------------------------------+
|1 |LINESTRING (10 10, 20 20, 10 40)|
+---+--------------------------------+
MultiLineString¶
from shapely.geometry import MultiLineString
line1 = [(10, 10), (20, 20), (10, 40)]
line2 = [(40, 40), (30, 30), (40, 20), (30, 10)]
data = [
[1, MultiLineString([line1, line2])]
]
gdf = spark.createDataFrame(
data,
schema
)
gdf.show(1, False)
+---+---------------------------------------------------------------------+
|id |geom |
+---+---------------------------------------------------------------------+
|1 |MULTILINESTRING ((10 10, 20 20, 10 40), (40 40, 30 30, 40 20, 30 10))|
+---+---------------------------------------------------------------------+
Polygon¶
from shapely.geometry import Polygon
polygon = Polygon(
[
[19.51121, 51.76426],
[19.51056, 51.76583],
[19.51216, 51.76599],
[19.51280, 51.76448],
[19.51121, 51.76426]
]
)
data = [
[1, polygon]
]
gdf = spark.createDataFrame(
data,
schema
)
gdf.show(1, False)
+---+--------------------------------------------------------------------------------------------------------+
|id |geom |
+---+--------------------------------------------------------------------------------------------------------+
|1 |POLYGON ((19.51121 51.76426, 19.51056 51.76583, 19.51216 51.76599, 19.5128 51.76448, 19.51121 51.76426))|
+---+--------------------------------------------------------------------------------------------------------+
MultiPolygon¶
from shapely.geometry import MultiPolygon
exterior_p1 = [(0, 0), (0, 2), (2, 2), (2, 0), (0, 0)]
interior_p1 = [(1, 1), (1, 1.5), (1.5, 1.5), (1.5, 1), (1, 1)]
exterior_p2 = [(0, 0), (1, 0), (1, 1), (0, 1), (0, 0)]
polygons = [
Polygon(exterior_p1, [interior_p1]),
Polygon(exterior_p2)
]
data = [
[1, MultiPolygon(polygons)]
]
gdf = spark.createDataFrame(
data,
schema
)
gdf.show(1, False)
+---+----------------------------------------------------------------------------------------------------------+
|id |geom |
+---+----------------------------------------------------------------------------------------------------------+
|1 |MULTIPOLYGON (((0 0, 0 2, 2 2, 2 0, 0 0), (1 1, 1.5 1, 1.5 1.5, 1 1.5, 1 1)), ((0 0, 0 1, 1 1, 1 0, 0 0)))|
+---+----------------------------------------------------------------------------------------------------------+